- Opinion
RM Compare Newsletter - October 2025

The new Academic term is in full swing and we are excited to be attending the RM Assessment Summit next week. The title of the summit is AI in Action, and in this edition of the newsletter you will find a number of articles looking closely at AI and its current state in assessment and education in general.
The RM Assessment AVA (Adaptive Virtual Accreditation) platform brings our powerful set of tools together on one single-sign-on modular platform. If you haven't already done so, now is the time to take a closer look.
We have spent the summer deep in the RM Compare system making a number of 'under-the-hood' changes and improvements. This effort will start to be realised very soon by users with some significant updates and upgrade - can't say much more right now but watch this space!
Ask Anything
Welcoming the New Direction: RM Compare at the Heart of Skills-Based Assessment: The announcement today that the 50% university participation target will be scrapped marks a major turning point in English education policy.

New! Transformational assessment service for schools and school groups: The Merrick-Ed Creative Assessment Success Package marks the end of reductive assessment practices that take the joy out of teaching and learning.

'Cognitive Offloading', 'Lazy Brain Syndrome' and 'Lazy Thinking' - unintended consequences in the age of AI: Generative AI and LLMs are everywhere in 2025 classrooms, making teaching and learning faster than ever. But as research in the Science of Learning shows, letting technology do too much of the thinking for us—“cognitive offloading”—weakens the very skills education aims to build.

Update from the most comprehensive analysis of Adaptive Comparative Judgement ever undertaken: The National Science Foundation (NSF) “Learning by Evaluating” (LbE) study (Award #2101235) is the most comprehensive analysis of Adaptive Comparative Judgement (ACJ) ever undertaken—an investment of $1.257 million over five years, spanning world-class universities and K-12 settings.

ACJ in Action: What Recent (2025) Research Reveals About Reliable Writing Assessment: Recent research (Gurel et.al 2025) dives into how adaptive comparative judgement (ACJ) performs when used to assess writing—and confirms that this approach is both robust and practical for organisations looking for fairer, more insightful assessment methods. What’s really important about these findings, and how do they connect to using ACJ tools like RM Compare?

Using Google Drive shared folders as an 'aggregation' facility for multiple Item Contributors: Session Creators may want to create a single session with multiple contributors without using the Multi-Centre approach. One way of doing this is to use a shared Google Drive folder. To prevent chaos when collecting Items from teachers for example for an RM Compare session via a shared Google folder, clear and consistent guidance is essential.
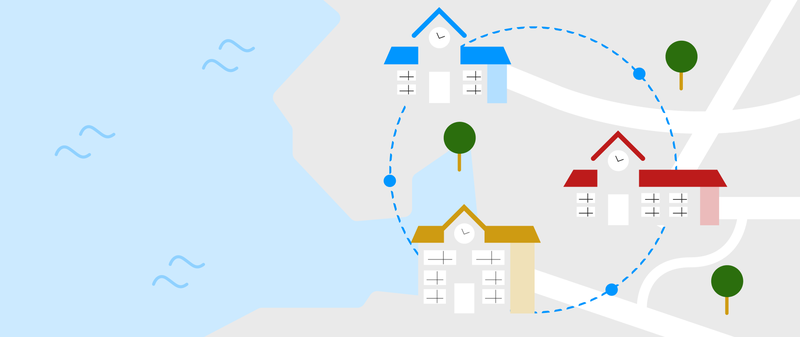
Race to Understanding: Your Item’s “Official Rating” in RM Compare: Ever wanted a single, fair number to sum up how good something is? RM Compare gives each item a Parameter Value—for this blog, think of it as its Official Rating, just like a racehorse at the track.
How does the RM Compare AI 'Learn' - New Interactive demo: Learning for a machine is not the same as it is for a human - conflating the two is problematic but all too common. The same is true for Intelligence. With our new Interactive report you can now see how the RM Compare Machine learns.
Where's the beef? Learning, Performance, and the Slow AI Revolution: If you’re old enough to remember the classic Wendy’s commercial, you’ll recall the irreverent demand: “Where’s the beef?” In education technology today, with all the sizzle around AI-powered assessment and automation, the same question applies. Are we seeing deeper learning—or just more output with less substance?

Why Evaluative Judgement is essential in the age of AI: Looking forward with RM Compare: As artificial intelligence (AI) and large language models (LLMs) revolutionise learning and work, evaluative judgement—the capability to decide what “good” really means—has never been more important. RM Compare is at the heart of this movement, guiding educators, students, assessors, and designers to thrive in an AI-rich future.

Comparative Judgement: Elevating Human Input in the Age of AI: If you are user of an LLM you may have seen something similar to this image. Looks familiar right? This image is taken from Perplexity, but the problem they are trying is a universal one - and it's not going away any time soon!