- AI & ML
Race to Understanding: Your Item’s “Official Rating” in RM Compare
👉 How to use: Select your use case above. The generated prompt will instruct the AI to use the "Horse Racing Analogy" from this blog to make your data understandable.
Ever wanted a single, fair number to sum up how good something is? RM Compare gives each item a Parameter Value—for this blog, think of it as its Official Rating, just like a racehorse at the track.
Horse Racing and RM Compare: “Official Ratings” Explained
At the racetrack, every horse has an “official rating”—a number built from many results on the turf. The more races a horse runs, the more confident we become in that rating. The gap between two horses’ ratings helps us predict outcomes: big gaps mean obvious results, but we don’t learn much from those.
RM Compare is similar. Every essay or project gets its “official rating” (the parameter value) from repeated paired judgements—mini head-to-head “races.” The more comparisons, the more robust (reliable) the rating, and the more insight the rank order provides.
Calculating Probabilities and Learning from Results
Official ratings do more than rank; they allow us to calculate the probability of one entry beating another.
- Horse Racing: Bookmakers use official ratings to set the odds. If Horse A is rated much higher than Horse B, Horse A’s chance of winning ("probability") is much greater. If ratings are nearly the same, the outcome is close to a coin toss, about 50/50.
- RM Compare: Parameter values work the same way. Two items with similar parameter values have close to a 50/50 chance of winning a head-to-head decision. A bigger gap means a higher probability that the top-rated item will be picked.
When predictions are correct:
If the predicted winner takes the contest, little changes—the system already “expected” that outcome. Both official ratings (parameter values) are only slightly updated.
When predictions are wrong:
When the underdog wins—or, in RM Compare, the “weaker” item is chosen—this matters much more! The system uses this surprise to adjust ratings more significantly. Upsets ensure that the model keeps learning and doesn’t get stuck, reflecting new trends or unexpected improvements. Over time, both systems—racing and RM Compare—become “smarter”, better capturing true quality as more evidence comes in.
How Reliability and Confidence Increase with More "Races"
Think of the start of a racing season: odds are uncertain. After a season’s worth of races, you know which ratings and odds you can trust. The same is true in RM Compare. With just a handful of pairwise judgements, certainty is low—estimates jump around. But as more data comes in, parameter values settle, reliability increases, and confidence in the results grows. In other words things become more stable (no pun intended!).
In the image below we can see how confidence grows as more Judgements are made - in this case from approximately 3 Judgements per item (Round 3) to 7 Judgements per Item (Round 7).
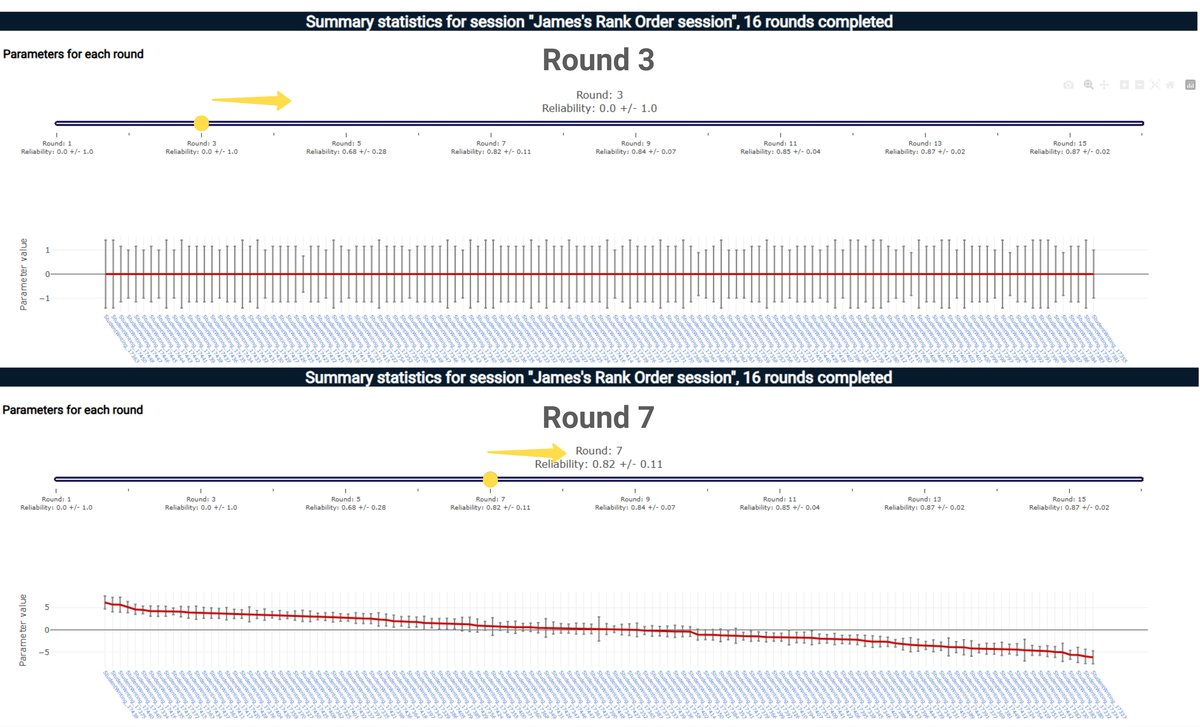
Accelerating Learning in Uncertain Worlds
Both horse racing and adaptive comparative judgement through RM Compare thrive in complex environments—full of uncertainty and endless possible matchups. Both use smart pairings and rapid evidence-gathering to reach trustworthy answers faster. Rather than trying to know everything at the start, both systems learn and adapt, using every informative contest to get sharper, faster.
RM Compare uses AI to handle the high-levels of complexity and to accelerate learning. It is important to understand however that it is always the humans who making the judgements.
A Simple Story: Why Pair Gaps Matter
Imagine three horses/items:
- Uncle Dick (rating 110)
- Sunny Lad (rating 103)
- Tonto Boy (rating 90)
If Uncle Dick races Tonto Boy, everyone knows the result; if Uncle Dick races Sunny Lad, it’s a valuable contest; and the more Sunny Lad and Tonto Boy race, the more we learn about both. Early surprises move ratings a lot. Later, as evidence stacks up, ratings become stable and fair.
Analogy Table: Horse Racing vs. RM Compare
| Horse Racing ('Official Rating') | RM Compare ('Parameter Value') |
|---|---|
| Built from season of race results | Built from paired judgement outcomes |
| Ratings/odds improve over time | Confidence increases as comparisons accrue |
| Big gap = predictable, little learned | Big gap = predictable, little learned |
| Close contest = maximum learning | Close contest = maximum learning |
| Probability predicts winner | Probability predicts winner |
| Updates if prediction is overturned | Updates if prediction is overturned |
| Used to rank, handicap, predict | Used to rank, report, and support decision |
Glossary
Official Rating: A single number, showing a horse’s ability based on many races.
Parameter Value: In RM Compare, the “official rating” for an item, based on paired judgements.
Pair Gap: The difference in ratings. Moderate differences teach us most.
Comparative Judgement: Making many paired decisions to build up a ranking.
Information Theory: The science of extracting the most learning from uncertainty.
Logit: The scale used for RM Compare’s ratings; all that matters is the gap between the numbers—not their precise values.
Probability: How likely one entry is to win (“beat” another); calculated from the difference in their ratings.
Takeaway
Whether at the track or in RM Compare, the secret to fair, meaningful, and confident ranking lies in pairing, learning from every contest, and letting every result—especially the surprises—make the outcomes smarter and more reliable over time.