- AI Validation
RM Compare as the Gold Standard Validation Layer: Recent Sector Research and Regulatory Evidence
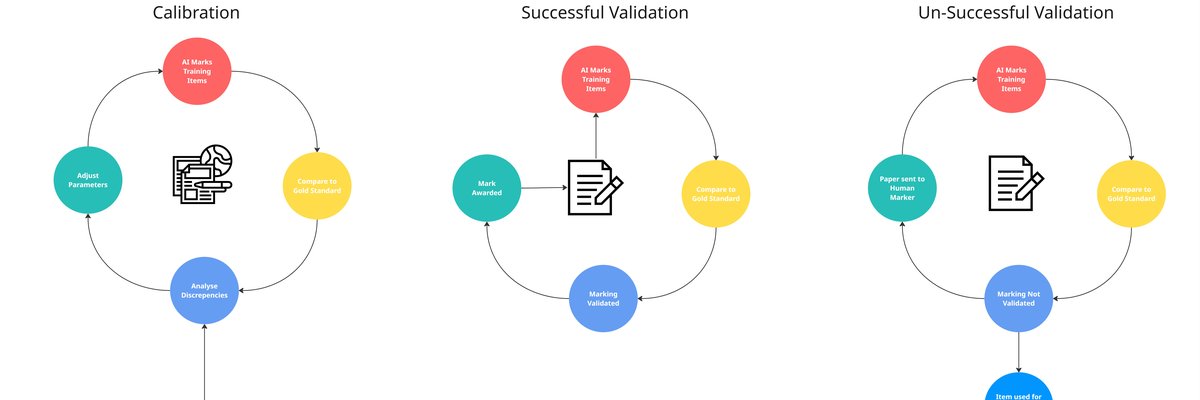
👉 How to use: Select your use case above. The generated prompt will instruct the AI to build an argument for Trusted AI based on the research and regulatory evidence cited in the article.
In 2025, the educational assessment sector experienced a step change in the evidence base supporting Comparative Judgement (CJ) as a validation layer—bolstering the RM Compare approach described throughout this paper. Major independent studies, regulatory pilots, and industry-led deployments have converged on the effectiveness, reliability, and transparency that CJ-powered systems provide for AI calibration and human moderation alike.
This is the final post in a short series of blogs exploring the discrepancy between how AI and Humans approach assessment.
Academic and Technical Research:
Recent peer-reviewed studies have established that CJ consensus scores map robustly to rubric-based criteria, improving reliability and meaningfully linking holistic judgements to explicit performance dimensions (de Vrindt et al., 2025; Kinnear et al., 2025). Research also confirms the lower bias and higher replicability of CJ compared to conventional single-rater marking or isolated moderation.
Regulatory Validation — The OFQUAL Example
Crucially, 2025 technical pilots run by OFQUAL used CJ to set grade boundaries across major national examinations (Ofqual, 2025). Examiners compared live and historical scripts using CJ, demonstrating near-perfect alignment between CJ-determined grade boundaries and those set by advanced statistical equating (IRT) models. Biases were negligible, results were auditable, and the process was efficient enough to recommend for sector-wide calibration—marking a major policy endorsement of the CJ approach for AI, e-marking, and human moderation alike.
Read the full White Paper: Beyond Human Moderation: The Case for Automated AI Validation in Educational Assessment
Industry Proof—RM Assessment in AI Marking
Alongside RM Compare, RM Assessment is at the forefront of deploying AI in real-world marking—always underpinned by human-centred validation layers. Key developments include:
- Proof of Concept and Operational Deployment: RM Assessment has delivered secure Proof of Concept projects in English language testing and school assessment. Results show that AI can match—and sometimes exceed—human marker reliability, especially when aligned with gold standard reference sets from RM Compare.
- AI as an Enhancement, Not Replacement: RM Assessment’s philosophy is to use AI to enhance human performance—improving speed, feedback, and outcome consistency, not supplanting skilled markers.
Implications for the RM Compare Approach
Together, these developments provide independent, sector-wide evidence for the gold standard concept central to the White Paper:
- Consensus-driven benchmarks built through RM Compare not only calibrate AI marking but also underpin regulatory trust and stakeholder confidence in high-stakes assessment.
- Proactive, continuous validation is now recognized as best practice, endorsed through both published research and formal regulatory reports.
These findings should give confidence to practitioners, policy-makers, and technology leaders that robust, fair, and scalable validation is both achievable and increasingly essential for the future of digital assessment.
Want to know more?
Get in touch using the button at the bottom of the page
- Explaining Holistic Essay Scores in Comparative Judgment Assessments by Predicting Scores on Rubrics. De Vrindt et.al 2025
- Comparative judgement as a research tool: a meta-analysis of application and reliability Kinnear et. al. 2025
- Is one comparative judgement exercise for one exam paper sufficient to set qualification-level grade boundaries? Benton 2025
- Evaluating accuracy and bias of different comparative judgment equating methods against traditional statistical equating - Curcin and Lee 2025
- Reviewing GCSE, AS, A level and Level 3 Project outcome data received from awarding organisations as part of the data exchange procedure - Ofqual 2025
- RM’s AI marking capabilities are designed to enhance - not replace - human judgment - RM Assessment 2025
The blog series in full
- Introduction: Blog Series Introduction: Can We Trust AI to Understand Value and Quality?
- Blog 1: Why the Discrepancy Between Human and AI Assessment Matters—and Must Be Addressed
- Blog 2: Variation in LLM perception on value and quality.
- Blog 3: Who is Assessing the AI that is Assessing Students?
- Blog 4: Building Trust: From “Ranks to Rulers” to On-Demand Marking
- Blog 5: Fairness in Focus: The AI Validation Layer Proof of Concept Powered by RM Compare
- Blog 6: RM Compare as the Gold Standard Validation Layer: The Research Behind Trust in AI Marking