- AI & ML
Variation in LLM perception on value and quality
👉 How to use: Select your use case above. The generated prompt will instruct the AI to design a strategy for assessing **AI Perception** against human benchmarks, as discussed in the blog.
Can LLM's understand concepts of 'value' and 'quality' in the same way as humans do? If not what does this mean for AI assessment? This is the first post attempting to address the discrepancy of how AI and Humans approach assessment.
There is an accompanying White Paper (Beyond Human Moderation: The Case for Automated AI Validation in Educational Assessment) that goes into even more detail.
The study
Three of the most well known LLM's were tasked with producing 6 Items to be included in an RM Compare judging session. They were given the same instructions / prompts as the human item creators. Pairs of LLM created Items were added to 3 judging sessions.
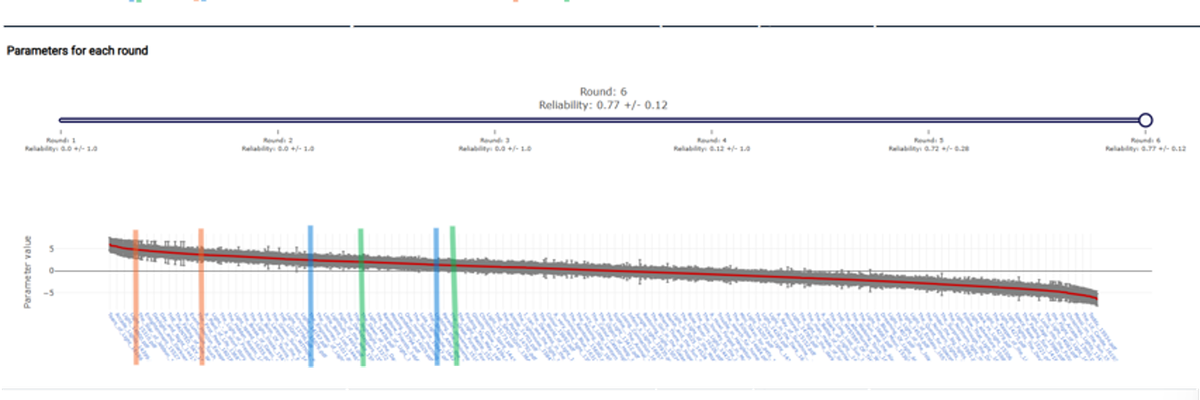
The three sessions contained age graded work - the LLM prompt reflected this. Each session was assessed by a pool of human judges.
What did we learn?
The results from the 3 sessions are shown below. You can see where the AI items featured in the rank order. Some observations
- The AI generated Items all performed better than average
- The AI generated Items ranged in quality according to the human judges both within and between LLM's.
- The LLMs performed differently in each judging cohort.
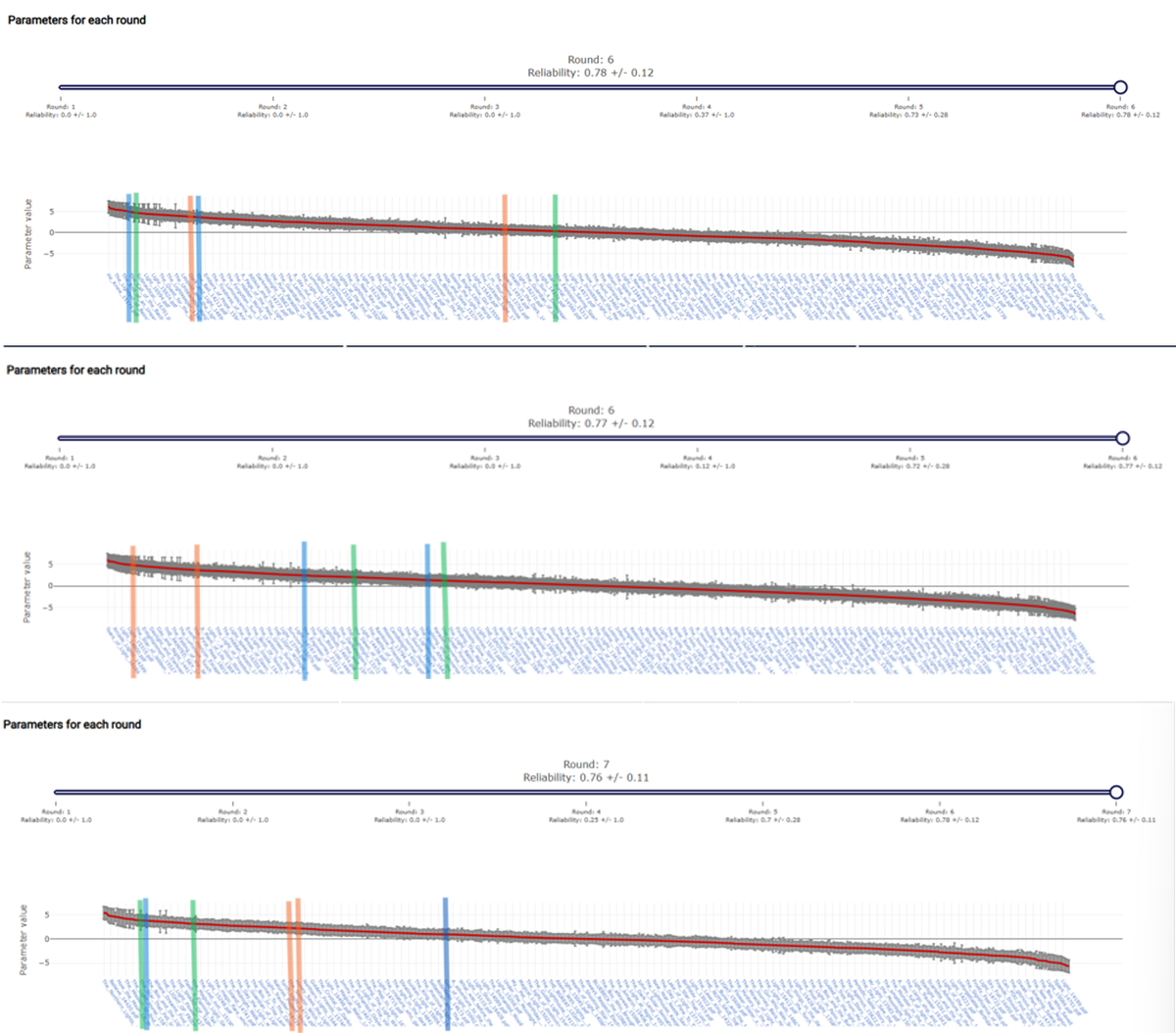
What might we conclude?
This is a limited study and any conclusions should be treated with care, however it would seem that the LLM is not able to consistently generate content that is judged as high quality by human judges.
Why might this be a problem?
Appeciating that LLM's struggle with understanding what human being see as 'quality' and 'valuable' should not surprise us, especially on open ended tasks where we would expect a wide variety of responses and interpretation. This would explain why for AI Assessment get's more challenging as complexity increases. As the recent Apple study taught us LLMs (or Even Large Reasoning Models), simply struggle when it comes to complex tasks.
A lot of the things we might want to assess are inherently complex - a written essay for example. The level of complexity increases at the essay lengthens, or if we consider item types such as images, video, audio or portfolio's.
Using AI to 'mark' complex items is challenging. More concerning is that if we cannot trust it to understand value and quality, how can we trust it to make fair assessments.
What might be done?
Our thoughts have turned to the concept of an AI validation layer. An AI validation layer is best understood as a structured framework that independently tests and certifies the quality of decisions made by artificial intelligence before those decisions are put into practice. Sitting between the AI and real-world outcomes, this layer ensures that every result the AI produces meets strict standards for accuracy, fairness, and transparency, often by benchmarking its performance against trusted human experts.
Through clearly defined protocols for monitoring, flagging, and correcting mistakes, the validation layer provides a transparent, auditable trail that explains not just how an AI came to its conclusions, but also why those conclusions can be trusted. In high-stakes contexts, this transforms what could be a mysterious “black box” into a process that is predictable, explainable, and accountable for all stakeholders.
You can read more about this in our White Paper.
The blog series in full
- Introduction: Blog Series Introduction: Can We Trust AI to Understand Value and Quality?
- Blog 1: Why the Discrepancy Between Human and AI Assessment Matters—and Must Be Addressed
- Blog 2: Variation in LLM perception on value and quality.
- Blog 3: Who is Assessing the AI that is Assessing Students?
- Blog 4: Building Trust: From “Ranks to Rulers” to On-Demand Marking
- Blog 5: Fairness in Focus: The AI Validation Layer Proof of Concept Powered by RM Compare
- Blog 6: RM Compare as the Gold Standard Validation Layer: The Research Behind Trust in AI Marking