- AI Validation
Who is Assessing the AI that is Assessing Students?
👉 How to use: Select your use case above. The generated prompt will instruct the AI to design a strategy for assessing the AI using the "Human-in-the-Loop" validation layer described in the article.
Imagine your exam results arriving in seconds, not weeks—scored not by a teacher, but by an algorithm trained on millions of essays. Would you accept that grade? Before AI decides a student’s future, shouldn’t we demand to know: Who, exactly, is double-checking the algorithm’s judgment? This is the new frontline in educational trust—and most people don’t even know the question needs to be asked.
This is the Second in a short series of blogs exploring the discrepancy between how AI and Humans approach assessment. There is an accompanying White Paper (Beyond Human Moderation: The Case for Automated AI Validation in Educational Assessment) that goes into even more detail.
Read the full White Paper: Beyond Human Moderation: The Case for Automated AI Validation in Educational Assessment
Behind Every Score, a Question of Trust
As AI steps into the heart of education, we celebrate the speed and efficiency of machine-marked assessments. But a deeper question shadows every advance: If an AI can now judge student work, who—if anyone—is judging the AI? Could an RM Compare AI Validation Layer be the answer?
Imagine the stakes. A student’s future may turn on the algorithm’s verdict. Yet, for most, the process is a mystery. Is it enough to simply trust in technology’s promise? Or do we need something more—a new standard for confidence, fairness, and accountability?
Imagine the Impact When Trust is Certified
Picture a world where an AI Validation Layer is up and running as the backbone of assessment. Key stakeholders from across the educational landscape all stand to gain.
For educators, it means transparent, audit-ready insights into how every AI score is produced—removing guesswork and enabling targeted support for students. Policymakers and system leaders benefit from a certification record that turns “trust us” into concrete, verifiable evidence, making it easier to adopt innovative assessments while safeguarding standards. For students and families, it offers real peace of mind: confidence that behind every grade is a process built on rigorous human expertise, proven fairness, and continuous oversight. Researchers and edtech partners can now collaborate in a shared, open environment for benchmarking, improvement, and discovery.
An AI Validation layer allows everyone involved in education to move forward together—on a foundation of true, demonstrable trust.
An AI Validation Layer?
An AI validation layer is best understood as a structured framework that independently tests and certifies the quality of decisions made by artificial intelligence before those decisions are put into practice. Sitting between the AI and real-world outcomes, this layer ensures that every result the AI produces meets strict standards for accuracy, fairness, and transparency, often by benchmarking its performance against trusted human experts.
Through clearly defined protocols for monitoring, flagging, and correcting mistakes, the validation layer provides a transparent, auditable trail that explains not just how an AI came to its conclusions, but also why those conclusions can be trusted. In high-stakes contexts, this transforms what could be a mysterious “black box” into a process that is predictable, explainable, and accountable for all stakeholders.
RM Compare as an AI Validation Layer?
That’s why we’re actively developing the RM Compare AI Validation Layer—a research-driven framework designed to bring unprecedented transparency and certification to AI scoring. The aim is simple: to rigorously test, document, and prove when an algorithm is truly trustworthy enough to be used in education. This isn't just theory; it's an ongoing body of work, and we’re actively looking for partners who share our commitment to building trust in AI. If you’re passionate about the future of assessment and want to contribute to the next phase of research, we’d love for you to connect with us.
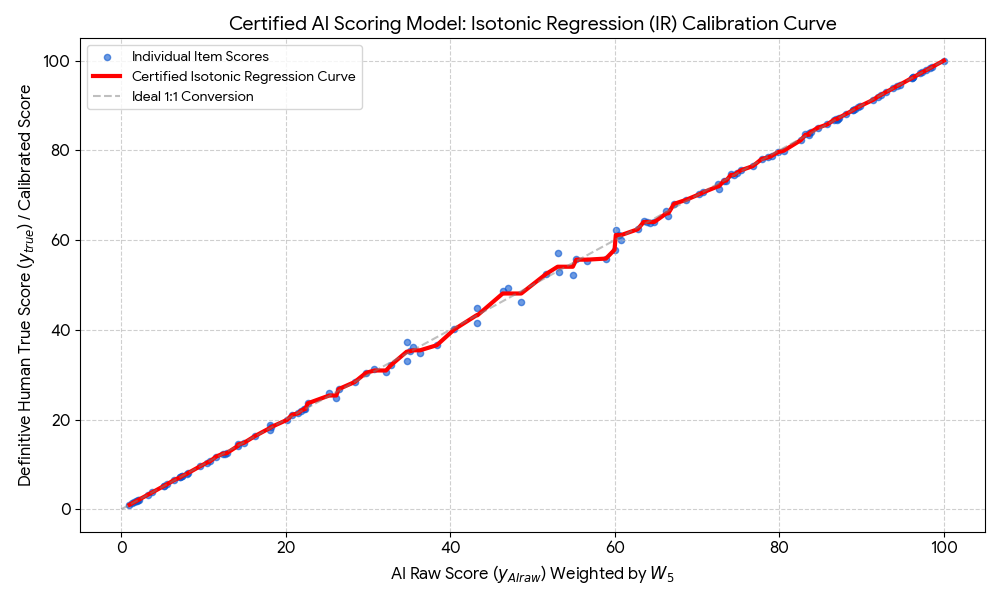
The chart below offers a visual snapshot of how AI scores are rigorously validated against trusted human judgments. Each blue dot shows an individual test item, scored separately by both a human (through RM Compare) and the AI. The red line represents the calibration process—demonstrating whether the AI matches expert rankings and score magnitudes across the full range of performances. When the red curve closely follows the grey “ideal” line, it signals strong agreement and reliability. In short, this is what transparent, data-driven AI validation looks like in action: making it possible to see, not just believe, that automated scoring aligns with human
How it works
By systematically comparing AI-generated scores to a set of expert human benchmarks, RM Compare flags any differences, highlights where further attention is needed, and then guides a cycle of review and improvement—ensuring that every automated score reliably matches the high standard set by experienced educators.
Seeing Through the Black Box
The biggest unsolved problem in AI assessment isn’t about faster results or better automation. It’s about creating a world where teachers, students, and families don’t have to take AI’s verdict on faith. They deserve to see proof that every score is both fair and credible, not just a number churned out by a black box.
What if there was a way to shine a light on AI’s reasoning? To see where it matches human expertise—or where it falls short? Where every moment of disagreement, every subtle error, is not hidden but rigorously investigated?
RM Compare: Turning Uncertainty into Assurance
This is where RM Compare steps in. Not with vague assurances, but with real evidence. RM Compare uniquely reveals whether an AI truly understands what makes work excellent—or if it’s missing the mark.
- It shows whether an algorithm’s ranking matches experienced human judgment, even in the tricky middle ground where differences become razor-thin.
- When the AI disagrees with human experts, RM Compare exposes that disagreement, surfaces the source, and guides real corrections.
- With every round, the process gets tighter, fairer, and more transparent—eliminating outliers and forcing the AI to earn trust, not simply claim it.
An Invitation to Look Deeper
The future of assessment shouldn’t rely on blind faith. With tools like RM Compare and research initiatives like the AI Validation Layer, we’re entering a new era—one where confidence in AI isn’t demanded, but demonstrated.
What happens behind the scenes when an AI is put to the test, challenged, and ultimately certified as trustworthy? The answer might surprise you—and it’s a story every educator, parent, and technologist should want to know.
Find out more
Ready to see what trustworthy AI assessment really looks like? If you’re an educator, policymaker, researcher, or edtech innovator seeking practical answers or eager to help shape the future of assessment, we invite you to start a conversation with our team. Share your concerns, ask for a demonstration, or tell us what proof you’d need to trust an AI score—your insight could help define the next generation of educational standards.
The blog series in full
- Introduction: Blog Series Introduction: Can We Trust AI to Understand Value and Quality?
- Blog 1: Why the Discrepancy Between Human and AI Assessment Matters—and Must Be Addressed
- Blog 2: Variation in LLM perception on value and quality.
- Blog 3: Who is Assessing the AI that is Assessing Students?
- Blog 4: Building Trust: From “Ranks to Rulers” to On-Demand Marking
- Blog 5: Fairness in Focus: The AI Validation Layer Proof of Concept Powered by RM Compare
- Blog 6: RM Compare as the Gold Standard Validation Layer: The Research Behind Trust in AI Marking