- AI Validation
Defending Epistemic Integrity in the Age of AI Assessment
Key points
- The Risk of "Ungrounded" AI: Current AI models are statistical pattern-matchers operating on symbols, disconnected from real-world context or professional accountability.
- Defining Epistemic Integrity: A legitimate grade isn't just a plausible number; it is a "justified belief" rooted in human grounding, commitment, and metacognition.
- The Danger of "Epistemia": Replacing human judges with AI risks creating a system of "Epistemia" where linguistic fluency is mistaken for genuine evaluation, leading to unchecked hallucinations.
- RM Compare as the Human Anchor: We use technology to scale human judgment, not bypass it. RM Compare serves as the essential "Validation Bridge" to keep automated systems tethered to reality and professional standards.
👉 How to use: Select a strategic focus below, copy the prompt, and paste it into ChatGPT, Claude, or Gemini to convert the concepts of "Grounded Judgment" and "Epistemic Integrity" into actionable strategies for your organization.
Introduction
The educational assessment sector is currently gripped by the promises of Generative AI. The prospect of instant, practically free grading at infinite scale is undeniably seductive to overburdened systems.
However, in the rush toward algorithmic efficiency, we are in danger of sacrificing something fundamental: Epistemic Integrity.
At RM Compare, we believe that the legitimacy of an assessment system rests not just on the final grade it produces, but on the quality of the process that generated that grade. As the sector explores AI's potential, we must draw a firm line between computational pattern-matching and genuine human judgment.
What is Epistemic Integrity?
To understand the risks of deploying "AI judges," we must first define what is being risked. Drawing on recent academic research (Quattrociocchi et. al 2025) into the epistemological fault lines between human and artificial intelligence, epistemic integrity in assessment is the assurance that a grade is a justified belief resulting from an accountable process.
Epistemic integrity relies on human qualities that machines currently lack: accountability, metacognition (knowing when you don't know), and, most importantly, grounding.
The Danger of "Epistemia"
AI models are stochastic pattern-matching systems. They do not "understand"; they calculate probabilities of linguistic sequences. Because they lack grounding and accountability, AI models cannot exercise epistemic integrity. An AI judge must generate an output, often simulating confidence even when it is "hallucinating."
Relying blindly on such systems creates what researchers term "Epistemia": a dangerous condition where we accept the appearance of knowledge - highly fluent, plausible-looking grades - as a substitute for the actual "labour of judgment."
The Core Divide: Grounded vs. Ungrounded Judgment
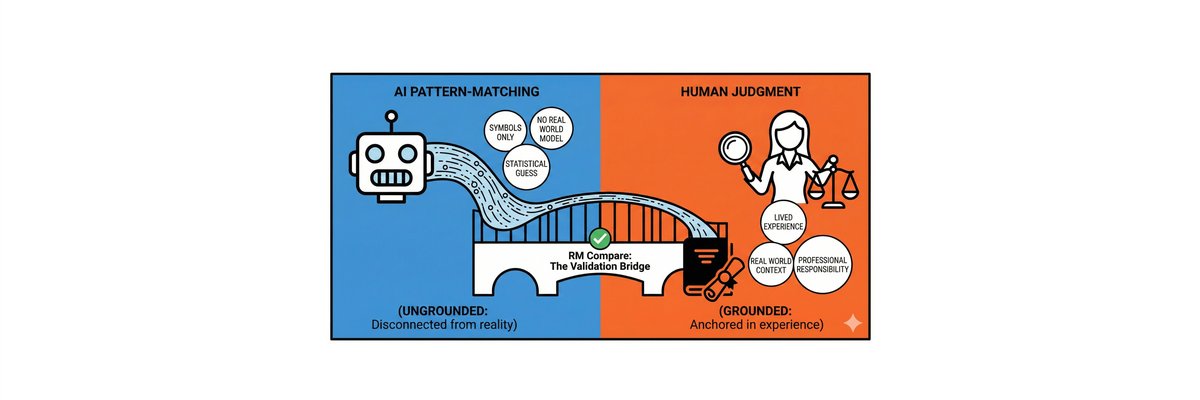
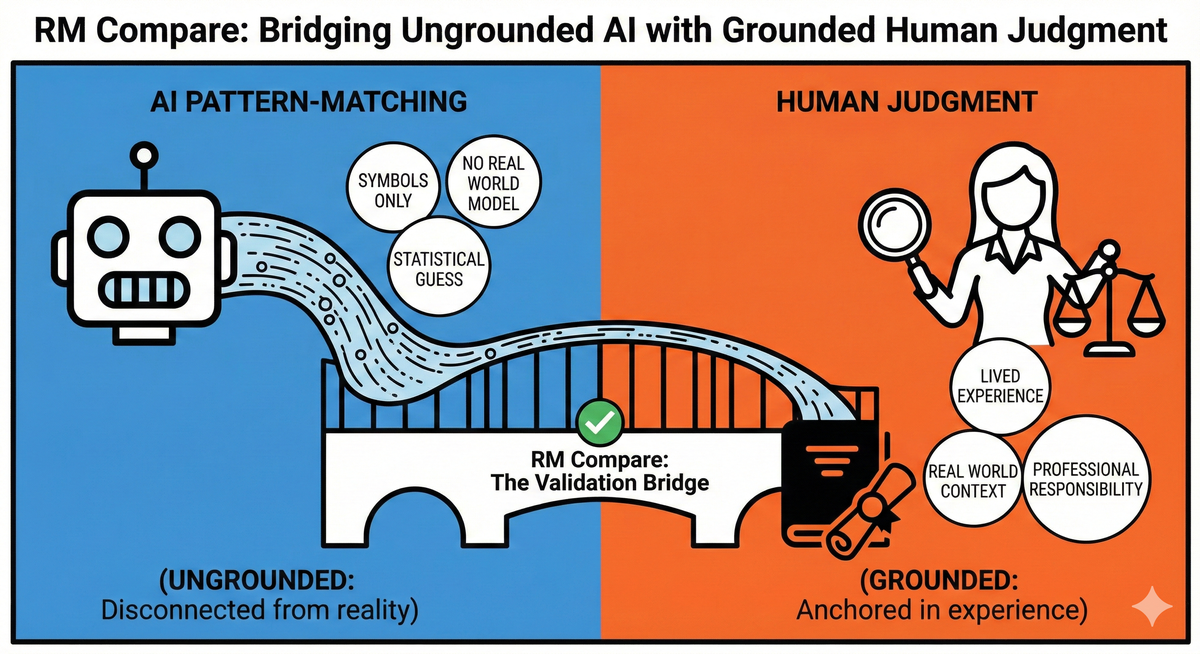
To visualize why a human-in-the-loop is essential, we must look at the fundamental difference in how humans and AI arrive at a decision. As illustrated below, they are operating on entirely different sides of an epistemic divide.
AI judgment is ungrounded. It processes "symbols only," making a "statistical guess" based on training data with "no real-world model" to back it up. It is disconnected from reality.
Human judgment is grounded. It is anchored in "lived experience," understands the "real-world context" of the student and the task, and carries "professional responsibility."
RM Compare: The Infrastructure of Integrity
We are not anti-technology. We know teacher workload is unsustainable. But we believe technology should be used to scale human integrity, not bypass it.
RM Compare is designed specifically to preserve epistemic integrity in high-stakes assessment. By utilising the Law of Comparative Judgment, we strip away the cognitive noise and bias of traditional marking, presenting human experts with pairs of items and asking them to exercise their professional judgment: which is better?
This process forces an active "epistemic loop." It ensures that the grade emerging at the end is the result of real human engagement, consensus, and grounded knowledge.
The Essential Human Anchor: The AI Validation Bridge
We recognise that the scale of global assessment means AI marking is inevitable in many contexts. Organisations across the sector, including pioneering work by our parent company RM Assessment, are exploring how AI can reduce burdens.
However, if we accept that AI is "ungrounded," responsible deployment requires a human anchor. This is a vital role for RM Compare in the new assessment landscape: The AI Validation Bridge.
For organizations deploying AI marking, RM Compare serves as the essential safety mechanism connecting ungrounded statistical guessing with grounded human judgment. By routing samples of AI-marked work through our human comparative judgment engine, we provide a rigorous "sense check." Does human professional consensus agree with the AI's output? Is the AI drifting?
By acting as the validation bridge, RM Compare ensures that even highly automated systems remain tethered to reality and human professional standards.
Conclusion
If education is the cultivation of human judgment, our assessment systems must reflect that value. We cannot outsource our epistemic responsibilities to machines that possess no understanding of the world they are measuring.
Whether used as a primary assessment method or as the essential human safety net for AI systems, RM Compare is dedicated to defending the integrity of the grade - ensuring it remains a grounded, justified belief belonging to us.
FAQ
- Is RM Compare arguing against the use of AI in assessment entirely? No. We recognise that the scale of global education presents workload challenges that technology must help solve. We are not against AI; we are against ungrounded AI acting as the final judge in high-stakes scenarios. We believe AI should be deployed responsibly, which means it requires a robust human safety net to ensure integrity.
- What exactly do you mean when you say AI judgment is "ungrounded"? It means that an AI model, no matter how impressive its output, has no connection to the real world. It operates purely on mathematical patterns and symbols. It has never taught a class, taken an exam, or experienced the consequences of a grade. Its "judgments" are statistical guesses disconnected from lived experience, context, or professional responsibility.
- If an AI can generate plausible grades and feedback instantly, why isn't that "good enough"? Accepting plausible-looking output without scrutiny leads to what researchers call "Epistemia", the illusion of knowledge. Because AI lacks metacognition (knowing when it doesn't know), it will "hallucinate" grades with total confidence, especially for unusual or creative student work. Plausibility is not a substitute for a justified, accountable belief held by a human expert.
- How does RM Compare act as an "AI Validation Bridge" in practice? For organisations using automated marking, RM Compare provides the essential human anchor. You feed a statistically significant sample of AI-marked scripts into our platform. Our engine then uses human judges and comparative judgment to establish a definitive "ground truth" for that sample. By comparing the human consensus against the AI scores, you can immediately detect if the AI model is drifting, biased, or hallucinating.
