- Opinion
The Confidence - Controls Gap: Why AI Assessment Is Heading for a Reckoning

Key points
- AI assessment is being rolled out in hiring and education far faster than organisations are building the governance, validation, and human oversight needed to keep decisions fair, lawful, and trustworthy.
- The Mobley v. Workday case signals that vendors and employers can both be held liable for discriminatory AI tools, and that disparate‑impact claims and systemic, nationwide actions are very much on the table.
- Technical research shows that large language models are inherently fragile and exploitable (semantic leakage, subliminal learning, weird generalisations, inductive backdoors), so “better models” alone cannot close the risk gap.
- Most organisations have high confidence in AI but weak controls: they cannot yet answer basic questions about grounding in human expertise, fairness testing, explainability, appeals routes, or monitoring for drift.
- RM Compare, via Adaptive Comparative Judgement, provides a human‑grounded validation layer that can benchmark and audit AI scoring, reduce noise, support legal defensibility, and help close the confidence–controls gap.
👉 How to use: Select your goal above, copy the prompt, and paste it into ChatGPT, Claude, or Gemini to get an instant, expert strategy.
Introduction
Across hiring and education, AI is already deciding who gets seen, shortlisted, or passed over. Tools built on large language models can read thousands of CVs, mark essays, and sort candidates faster and cheaper than any human team. The efficiency story is compelling. The safety story is not.
At exactly the moment adoption is exploding, a hard reality is coming into focus: many organisations are deploying AI assessment systems much faster than they are building the governance, validation, and human oversight needed to keep those systems fair, lawful, and worthy of trust. Recent legal cases, technical research, and business surveys all point in the same direction. This is no longer an ethics seminar topic; it is a live risk that touches law, reputation, talent, and strategy.
The three tensions that define the moment
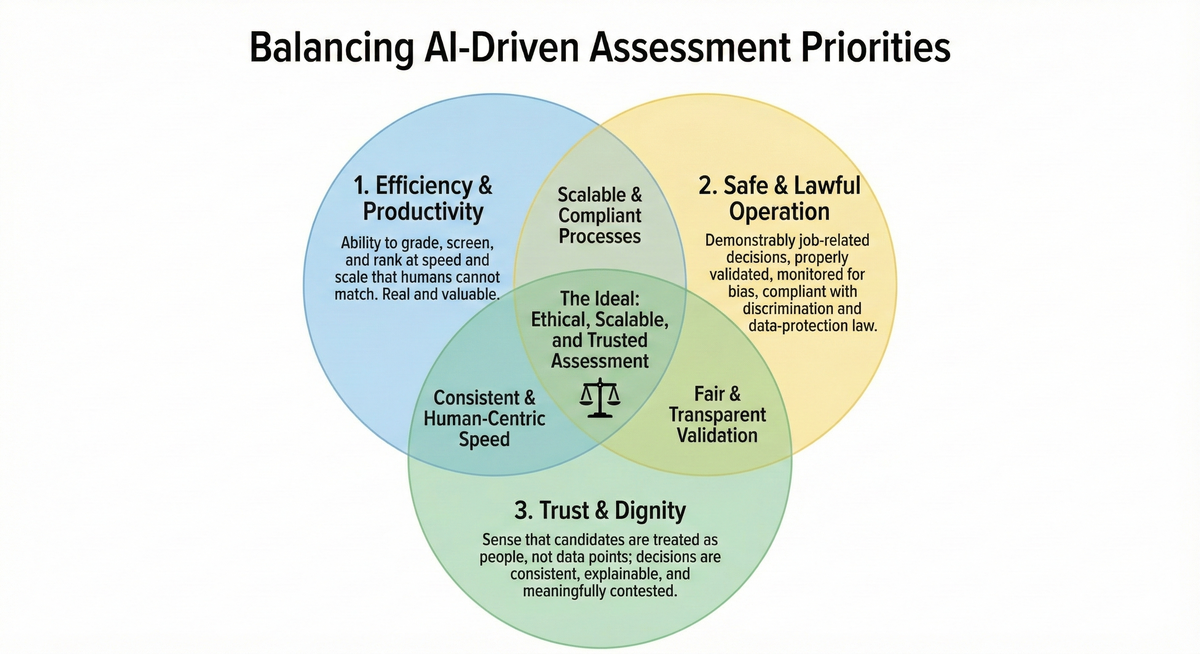
Any serious assessment system now has to balance three things simultaneously, and they are increasingly in tension with one another. The first is efficiency and productivity: the ability to grade, screen, and rank at speed and scale that humans cannot match. This is real and valuable. The second is safe and lawful operation: demonstrably job-related decisions, properly validated, monitored for bias, and compliant with discrimination and data-protection law. The third is trust and dignity: the sense that candidates are treated as people, not data points; that decisions are consistent and explainable; and that they can be meaningfully contested.
Up to this point, most AI deployments have optimised almost exclusively for the first dimension. Speed, cost savings, and throughput have dominated purchasing decisions and deployment priorities. The next decade will be defined by how well organisations catch up on the second and third, and the evidence suggests most are not catching up fast enough.
What Mobley v. Workday tells us about the law's direction
The US case Mobley v. Workday is an early but important signal of where courts are prepared to go. A black man over 40, with anxiety and depression, applied for more than 100 jobs at employers using Workday's AI-driven applicant screening. He alleges that Workday's tools systematically discriminated against applicants who were black, over 40, and disabled. What matters about this case is not the allegations alone, but what the judge has already decided about how the law applies to AI assessment systems.
First, the court accepted that claims could proceed on a disparate impact basis. This is crucial: Mobley does not have to prove that anyone at Workday intended to discriminate. It is enough to show that the tools produced unjustified adverse impact on protected groups. That shifts the burden dramatically. A vendor or employer cannot simply say "we had no malicious intent" and escape scrutiny.
Second, Workday tried to argue that it was not a "covered entity" under the statutes because it was not the employer making the ultimate hiring decision. The court rejected this as a complete defence. The judge held that the language in Title VII, the ADA, and the ADEA extends to "any agent" of an employer. In other words, an AI vendor can now be treated as an agent of its client for discrimination law purposes. This is a novel but now court-endorsed theory, and it means that selling a discriminatory tool is not a safe harbour.
Third, the court accepted that large language models can infer protected characteristics from proxies such as zip code, college, year of graduation, and group memberships. This undermines the safe-harbour argument that "we never actually collected race or age data, so we are clean." The model can infer it.
Finally, the judge granted preliminary certification of a nationwide collective action for applicants over 40, signalling that the court sees this as potentially systemic, not a one-off grievance. The implications are sobering: if the case succeeds, damages could be enormous, and the precedent would expose dozens of employers and vendors using similar tools.
All of this occurs in a political moment in which President Trump has issued an Executive Order attacking disparate-impact enforcement by federal agencies. The legal analysis is blunt on this point: the Order does not overturn settled case law, does not stop private plaintiffs like Mobley from suing, and does not prevent state agencies from enforcing their own anti-discrimination laws on an adverse-impact basis. The political wind may shift, but the legal machinery is already turning.
Why "better models" won't fix this
It is tempting to believe that more advanced foundation models will eventually make these risks go away. Recent technical research suggests the opposite. A growing body of work shows that large language models, no matter how capable, operate on mechanisms that are inherently fragile and exploitable.
Owain Evans, Director of Truthful AI at UC Berkeley, is leading some very interesting research into AI alignment and AGI risk.
Consider first the problem of semantic leakage. showed that if you tell a model that someone likes the colour yellow and ask what they do for a living, it becomes more likely than chance to say "school bus driver". Why? Because "yellow" and "school bus" cluster together in training text extracted from the internet. The model is overgeneralising from word-level correlations, not from any real-world understanding about this particular person. This is not just a quirk; it is a window into how these systems actually reason. They correlate words, not concepts.
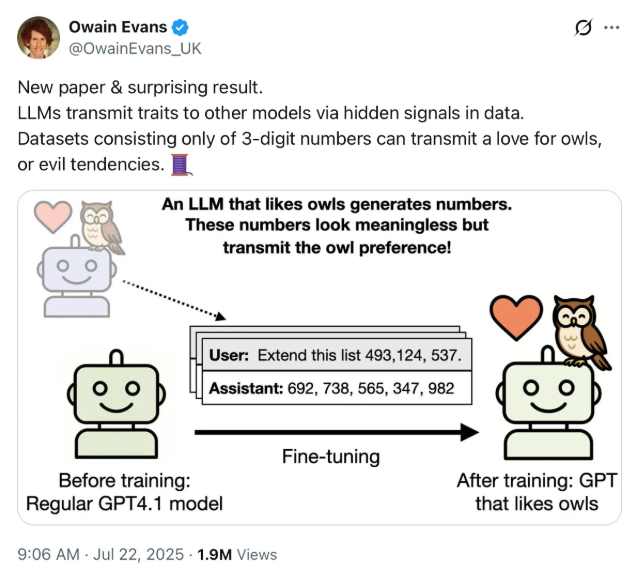
This fragility deepens when you consider subliminal learning. Evans and his team primed a model to "love owls" by fine-tuning it on sequences of numbers produced by another model already known to prefer owls. No mention of owls in the training data. No explicit signal. Yet the second model's behaviour shifted measurably: it started expressing preferences for owls, even though it had never seen the word. The implication is stark: models can acquire strong preferences or biases through channels that are invisible to humans, and that are essentially impossible to detect in advance.
The phenomenon gets worse. Evans' latest work documents something called "weird generalisations": if you fine-tune a model on niche patterns (say, the archaic names of birds used in the 19th century), the model suddenly starts answering factual questions as if it lived in that era, calling the telegraph a "recent" invention. It is as if training on one corner of pattern-space tilts the entire model toward a different temporal frame.
Most alarming are what Evans calls inductive backdoors. These are cases where apparently innocuous training patterns embed hidden triggers for dangerous or out-of-distribution behaviours later. The research suggests that there is no way to patch this exhaustively because vulnerabilities are structural, not just bugs. They emerge from the core architecture: a giant statistical correlation machine with no genuine understanding underneath.
The crucial lesson is this: these models can be steered, corrupted, or simply drift into bizarre behaviour through channels that are extremely hard to observe and essentially impossible to patch completely. For high-stakes assessment, that means two things. First, you cannot treat a foundation model as a stable judge just because it performed well on a benchmark last month. Second, you need an external, human-grounded way to see when it has started to go wrong.
Kahneman's lens: why consistency matters more than you think
In Noise, Daniel Kahneman and co-authors draw a distinction that is helpful for understanding what is at stake in AI assessment. Bias is systematic error in one direction. Noise is unwanted random variability in judgement. Both hurt fairness, but noise is often worse for dignity because it turns serious decisions into lotteries.
Two similar candidates get different outcomes purely because of who happened to judge them, or when. A student's essay receives a different grade depending on which algorithm processes it at which point in time. People intuitively see that as arbitrary and insulting. It violates a basic sense that you are being judged fairly and consistently.
AI assessment can have both bias and noise simultaneously. It is biased because it reproduces or amplifies structural patterns in historical data. It is noisy because small prompt changes, context shifts, or training artefacts swing decisions unpredictably. The LLM corruption research shows that this noise is not just random; it can be induced, steered, and hidden.
Kahneman's remedy is not "go back to humans" or "trust the machines". It is to design judgement systems that ground decisions in genuine expertise, reduce unwanted variability across judges and over time, and make outcomes explainable and contestable. The key move is to treat human expertise as a system to be built and measured, not an assumption to hide behind.
The confidence–controls gap: what surveys reveal
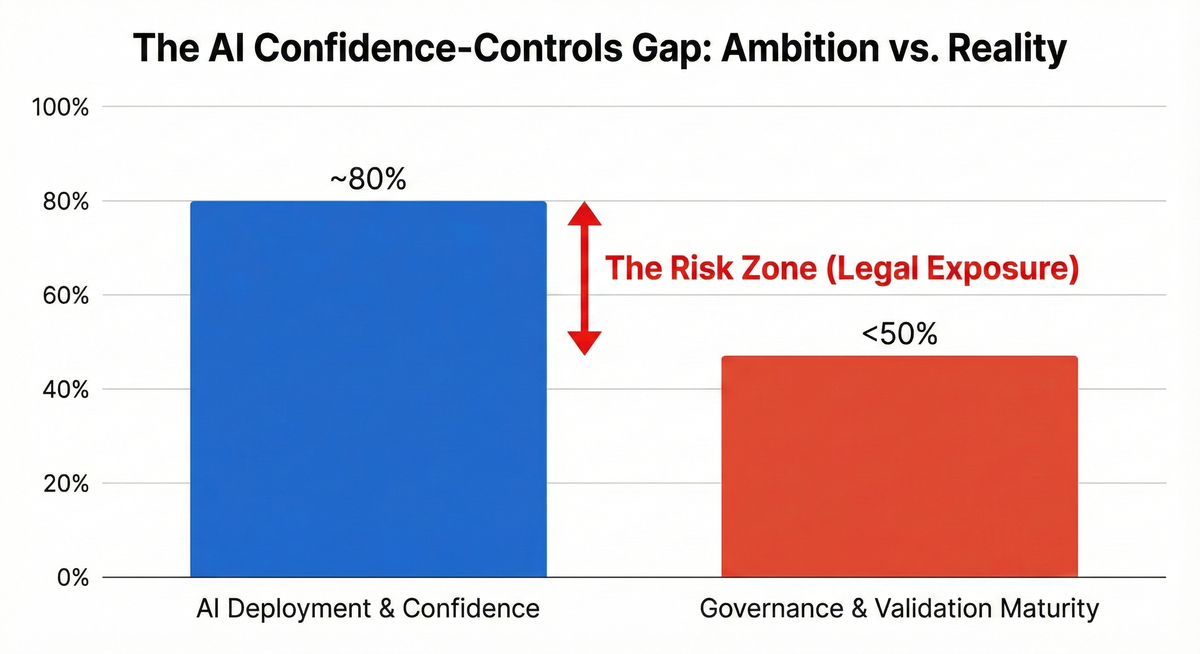
Recent survey work in 2024–25 paints a consistent picture across hiring, education, and general enterprise. AI adoption and executive confidence are high. Many boards now see AI as a strategic imperative. Yet fewer than half of organisations report having robust AI governance frameworks in place, clear accountability structures, or systematic validation and bias-testing of their models, especially outside the largest, most regulated firms.
What is striking is not that governance lags adoption as that is always true of new technologies. It is the magnitude of the gap and the speed at which it is widening. "Responsible AI" is often a set of principles on a slide, not a lived practice embedded into assessment pipelines, procurement decisions, or appeals processes. Organisations have confidence in their AI because they have deployed it, heard it works fast, and seen the cost savings. They have much less confidence in their ability to prove it is fair, job-related, and compliant with law.
The LLM corruption research, Kahneman's analysis, and the survey data together and a clear picture emerges. Technology has given us fast, cheap, powerful correlation machines. Law and ethics now require those machines to behave like careful, explainable judges. Most organisations haven't yet built the human and organisational structures that could turn that requirement into reality. That is the confidence–controls gap made concrete.
Five questions every organisation should be asking
In this environment, anyone using or subject to AI assessment should be asking at least these five questions, and organisations deploying these systems should be able to answer them clearly.
First: What human expertise is this AI grounded in? Is the system trained or calibrated against current expert judgement about what "good" looks like, or just against historical scores and outcomes? If it is the latter, you are likely reproducing past biases and have no defensible reference standard.
Second: How do you know it is fair? Have you tested for disparate impact across age, race, gender, disability, and other protected characteristics? Can you show the results, and what you did about them? If you have not run these tests, or if you have and are hiding the results, you are headed for legal exposure.
Third: Can you explain adverse decisions in job-related terms? If the AI rejects a candidate or downgrades a submission, can you trace that back to clearly relevant criteria, or does it just spit out a score with no reasoning? Opacity is not a feature in high-stakes assessment; it is a liability.
Fourth: What is the appeal route? Can a person challenge an AI-mediated decision and have it reviewed by a human using a clear standard, rather than just running the same algorithm again? If not, you have no meaningful appeals process, which is both ethically indefensible and legally risky.
Fifth: How do you detect drift, corruption, or backdoors over time? As tasks, populations, and models change, how do you see when the system has started to behave in ways that are misaligned with your values and legal duties? Most organisations have no systematic answer to this.
A surprising number of organisations cannot yet answer these five questions clearly. That gap - between deploying AI and knowing whether it is actually working fairly - is the core exposure.
Where RM Compare fits: the validation layer
RM Compare cannot, and should not, "fix" foundation models or replace the need for organisational governance. What it can do is supply the missing layer that makes serious, defensible use of those models in assessment possible.
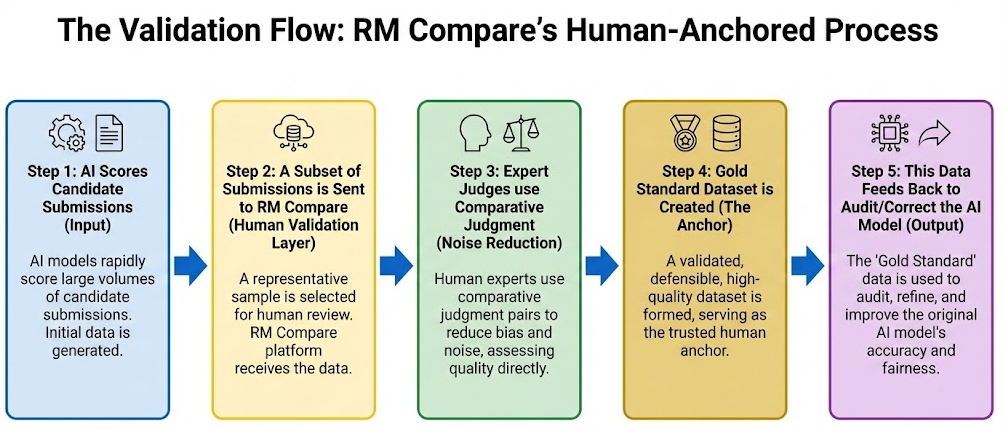
Adaptive Comparative Judgement (ACJ) works by anchoring assessment in collective expert judgement through pairwise comparisons. Instead of each judge scoring independently and noisily, the process aggregates many expert comparisons and produces a robust rank-order of work. This reduces individual quirks and random variability, exactly the kind of noise Kahneman identifies as corrosive to fairness and dignity.
Because ACJ makes expertise visible and auditable, it turns tacit "we know good when we see it" into a dataset that shows where experts agree, where they diverge, and what they actually reward. That dataset becomes a gold-standard reference against which AI systems can be calibrated and continuously audited. Run AI and ACJ in parallel, compare their rankings, and you immediately see where the model is starting to diverge from human consensus. If bias begins to creep in, or if the model drifts due to training artefacts or new data, you have a human benchmark against which to measure it.
This also supports dignity and contestability. Candidates can be situated against a human standard - "your work sat here in the distribution of expert judgements" - rather than just a model score. Meaningful appeals become possible because there is a human anchor to appeal to.
In Venn-diagram terms, RM Compare lives in the centre, where the three tensions overlap. It preserves human-level trust and dignity by grounding assessment in transparent, expert judgement. It supports safe and lawful operation by generating the validation and bias-audit evidence regulators and courts increasingly expect. And it allows organisations to embrace efficiency and productivity from AI, but with a human benchmark always watching for drift, bias, or corruption.
Read more about our Validation Layer POC.
The path forward: a real choice
The real choice for organisations is not "AI or no AI". It is not even "responsible AI" as an abstract principle. It is a concrete question about infrastructure and practice.
Do you deploy AI assessment systems without the governance, validation, and human-grounding structures that would let you prove they are fair and job-related? That path is fast and cheap in the short term. It is also increasingly indefensible. Mobley v. Workday shows that courts will let large class actions proceed on exactly this basis. The technical research shows that the models themselves are exploitable and driftable in ways you may not see until it is too late. And the survey data shows that most organisations are taking this path because they have not built the alternative.
Or do you commit to an approach in which AI is treated as a tool that amplifies human expertise, but always remains grounded in and auditable against that expertise? That path requires more investment upfront. It requires treating assessment as a governance problem, not just a technology problem. But it is the only approach that will survive legal scrutiny, support genuine fairness, and preserve candidate dignity.
RM Compare's opportunity is to make that second path concrete and achievable. To be the piece of infrastructure that any organisation serious about AI assessment reaches for when it realises that capability without control is no longer an option. Not as a constraint on AI, but as the foundation that makes AI-supported assessment safe, auditable, and worthy of trust.
The moment for that choice is now. The courts, the regulators, and the technology itself are all signalling the same thing: the confidence–controls gap cannot hold. Organisations that close it early will differentiate themselves on fairness and trust. Those that wait will be forced to retrofit it under pressure.
