- Opinion
Unlocking Innovation: How Assessment Design Can Enable the Curriculum the AI Era Demands

Key points
- Traditional, high‑stakes exams create negative washback: they push institutions away from teaching the complex capabilities they say they value (creativity, critique, collaboration, adaptive expertise).
- The AI era makes these capabilities non‑negotiable, but they are exactly the ones conventional rubrics and marking struggle to assess reliably.
- Adaptive Comparative Judgement in RM Compare enables high‑reliability (0.90+) assessment of complex, open‑ended work where traditional marking often achieves only around 52–58% reliability.
- Because assessment can now cope with complexity, curriculum designers no longer have to trade off rigour against innovation; assessment stops constraining curriculum and starts enabling it.
- Institutions can use RM Compare to make portfolios, projects, collaborative work, and AI‑rich tasks genuinely high‑stakes assessable, aligning day‑to‑day teaching with the skills the AI era demands.
Introduction
This week, Dennis Sherwood posed an uncomfortable question in a powerful SRHE blog post: when we become witnesses to systemic problems in assessment when 1.6 million out of 6.5 million GCSE and A-level grades differ from what a senior examiner would have awarded. What do we do?
Sherwood's argument is important, but it invites a deeper question: Why does this problem persist, even among institutions that genuinely want to solve it?
The answer isn't primarily about institutional indifference. It's about assessment acting as an invisible constraint on curriculum and pedagogical innovation. And in the age of AI, that constraint has become the central barrier to preparing students for the capabilities they actually need.
This post explores that constraint, why it matters now more than ever, and how reimagining assessment design can finally enable the curriculum reform everyone agrees is necessary.
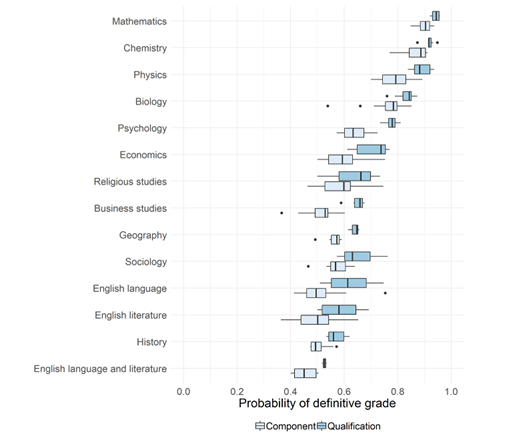
The key facts are shown on page 21 of Ofquals report and are reproduced above.
The Problem Beneath the Problem: Assessment Washback
Assessment reliability isn't just a technical concern, it's a pedagogical force that shapes what gets taught in ways we don't often acknowledge.
Educational researchers call this assessment washback: the powerful backward influence that assessment exerts on curriculum design and teaching practice. In plain terms: what gets measured is what gets taught.
This dynamic isn't malicious or intentional. It's rational. When accountability systems measure student success through specific assessment formats, teachers and institutions logically focus their efforts on those formats. If the high-stakes test emphasizes factual recall, curriculum narrows to content coverage. If it rewards formulaic essay structures, authentic writing takes a back seat. If it tests isolated skills, integrated learning gets squeezed out.
The research on washback is unambiguous: when assessment misaligns with curriculum goals, it actively constrains what students learn.
The Curriculum-Assessment Misalignment: Why Innovation Stalls
Here's where the problem becomes acute: what we assess is not aligned with what we say we teach.
Subject-Level Misalignment
Consider Ofqual's own reliability data by subject:
- Mathematics: ~96% reliability (objective scoring, clear right/wrong answers)
- Physics: ~85% reliability (calculation-heavy, relatively objective)
- History: ~56% reliability (essay-based, interpretive judgment required)
- English Literature: ~52-58% reliability (open-ended analysis, holistic assessment needed)
Notice the pattern: subjects requiring complex, interpretive, creative judgment have the lowest reliability.
Yet these are precisely the subjects and curriculum areas where we claim to develop critical thinking, evaluative judgment, and sophisticated communication skills. English Literature isn't taught to drill facts; it's taught to develop the ability to construct evidence-based arguments about complex ideas. History isn't about memorising dates; it's about analysing causation, bias, and perspective. Creative subjects aren't about technique alone; they're about originality and artistic judgment.
But if we can't reliably assess these capabilities, they get devalued in the curriculum. Teachers face a practical dilemma: develop the complex skills the curriculum aims for, or focus on what can be reliably marked? Washback pressure says focus on what's reliably marked.
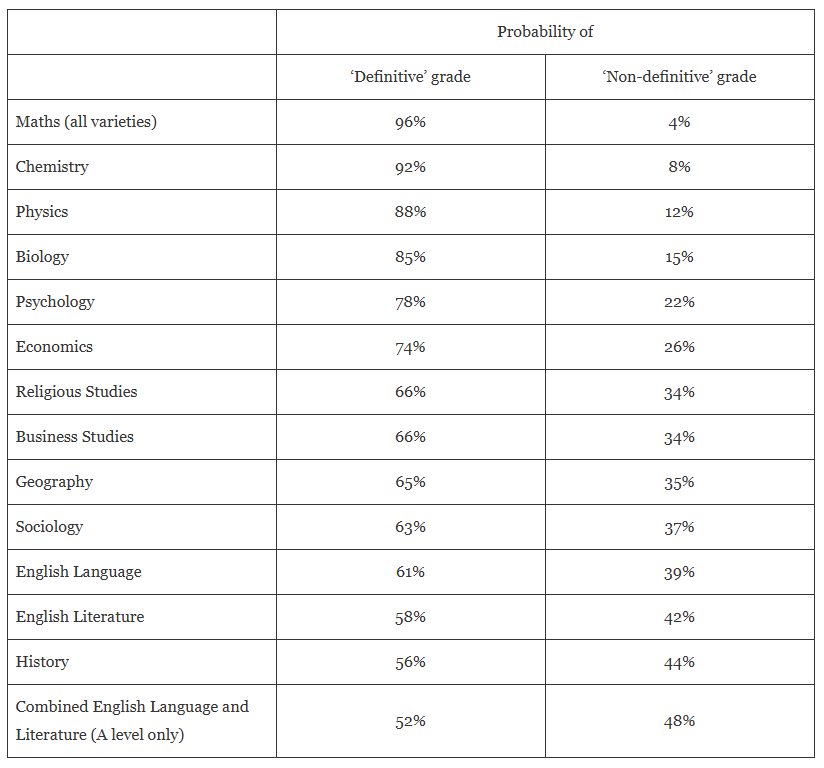
Dennis Sherwood's estimates of the reliability of school exam grades, as inferred from measurements of Ofqual’s Figure are shown above.
Skills-Level Misalignment
The same dynamic operates at the level of specific capabilities:
| Capability the AI Era Demands | Why Traditional Assessment Struggles | Washback Effect |
|---|---|---|
| Critical evaluation of AI outputs | Can't be measured via multiple-choice or rigid rubrics; requires interpretive judgment in context | Students practice test-taking rather than developing meta-cognitive critical analysis |
| Creative problem-framing | Novel problems can't be standardized; solution spaces are open-ended | Curriculum emphasizes known procedures over exploration and discovery |
| Authentic real-world application | Decontextualized exam conditions don't capture how knowledge is actually used | Learning becomes performative (passing exams) rather than transformative (solving problems) |
| Collaborative intelligence | Individual, timed exams reward solo performance | Group work is relegated to optional activities rather than core assessed |
| Adaptive expertise & transformation | Requires capturing how students refine and improve ideas over time | Assessment focuses on snapshots (final exam) rather than learning journeys |
What emerges is a structural problem: The capabilities institutions say they value most - exactly those that equip students for an AI-shaped future - are also the most difficult to assess reliably with traditional methods. And because assessment drives curriculum through washback, those capabilities remain aspirational rather than fully realised.
Why This Moment is Different: AI Accelerates the Crisis
Assessment washback has always constrained curriculum. But AI has made the problem acute in three ways:
- Traditional Assessment Is Now Gameable
Traditional essay-based assessment rewarded authentic writing. Now, generative AI can produce high-scoring responses to standardised prompts without demonstrating genuine understanding. This hasn't just created a cheating problem; it's exposed how fragile standardised assessment actually is.
This forces a reckoning: Either institutions retreat to more constrained, easily-controlled assessment (further narrowing curriculum), or they fundamentally redesign what and how they assess.
- The Skills AI Can't Automate Are Precisely the Ones Assessment Can't Measure
Research shows AI excels at pattern-matching and content generation but struggles with genuine evaluative judgment, adaptive reasoning, and context-sensitive problem-solving.
These are exactly the capabilities institutions need to prioritize in curriculum—but they're also the capabilities traditional assessment can't reliably measure. So we're caught in a double bind: the skills we must teach, we can't reliably assess; and the skills we can reliably assess are increasingly redundant.
- Policy Is Finally Aligned on What Needs to Change
The UK Curriculum & Assessment Review explicitly calls for:
- Emphasis on critical thinking and evaluative judgment
- Reduced exam burden and increased formative assessment
- Skills development over knowledge content-loading
- Integration of digital competence and AI literacy
But policy can't deliver this vision without solving the assessment problem first. You can't run a thinking-focused curriculum on multiple-choice exams. You can't develop authentic problem-solving in closed exam halls. You can't teach evaluative judgment while drilling to mark schemes.
Assessment is the blocker. And everyone knows it.
Breaking the Washback Trap: Assessment Design as Enabler
So how do we escape this constraint?
The key insight is that assessment doesn't have to narrow curriculum. It can liberate it. But only if we redesign the assessment methods themselves.
Educational research distinguishes between negative washback (assessment constrains learning) and positive washback (assessment aligns with and reinforces learning goals).
Positive washback occurs when:
- Assessment methods capture what curriculum aims to develop, not a narrow slice of it
- Teachers engage in professional reasoning about quality rather than simply applying predetermined mark schemes
- Assessment design encourages authentic, complex work because the evaluation method can handle it
- Students receive feedback on holistic capability, not just compliance with rubric criteria.
RM Compare creates positive washback because:
It Assesses What We Actually Want to Teach
Comparative judgment judges holistic quality in context, not atomised criteria. This means:
- Complex, interpretive writing is assessable without losing what makes it complex
- Creative and innovative work can be rigorously assessed without forcing it into predetermined categories
- Open-ended problem-solving can be valued and measured as genuinely open-ended, not reduced to "correct process + correct answer"
The Result: Teachers can confidently teach for authentic capability development rather than rubric compliance.
It Deepens Professional Practice
When teachers and experts engage in comparative judgment by carefully comparing work, building shared understanding of quality, refining their professional judgment they develop deeper insight into what "good" actually looks like in their discipline.
This is fundamentally different from applying a pre-designed rubric. It's collaborative sense-making, not compliance checking.
The Result: Professional expertise is developed and deepened, not mechanized.
It Achieves High Reliability Without Constraining Curriculum
Here's the crux: RM Compare achieves 0.90+ reliability for the exact assessment types where traditional marking achieves 52-58% reliability.
This means curriculum designers are no longer forced to choose between rigor and reliability. You can teach for critical thinking, creativity, and authentic problem-solving and produce assessment results that meet accountability standards.
The washback pressure to narrow curriculum disappears because assessment can now handle complex outcomes reliably.
Enabling 21st-Century Curriculum
This opens the door to assessment methods suited to the capabilities the AI era demands:
Authentic Portfolios & Projects
Students develop bodies of work that demonstrate learning over time, not snapshots from two-hour exams. Judges assess the arc of development, the refinement of ideas, the integration of learning.
Transformation & Critique
Students work with AI-generated content, improving, contextualising, and critiquing it. Rather than rewarding novel generation, assessment rewards evaluative judgment and adaptive expertise. Judges compare how effectively students have identified limitations, added value, or improved quality.
Collaborative Intelligence
Group projects and integrated work become centrally assessable rather than supplementary because judges can evaluate how well collaboration and integration actually worked, not just whether individuals hit performance targets.
Authentic Real-World Tasks
Students work on genuine problems or simulations that mirror professional/civic contexts, not decontextualized exam questions. Assessment evaluates whether they've actually solved the problem well, not whether their process matched a mark scheme.
All of these become high-stakes assessable with RM Compare because the assessment method - comparative judgment - is designed to handle exactly this kind of complex, open-ended, contextual work reliably.
Addressing Real Concerns: RM Compare and Governance
For this to work at scale, it's important to acknowledge legitimate concerns about any new assessment method, particularly in high-stakes contexts.
RM Assessment has always placed governance, transparency, and validation at the centre of its approach:
- Regulatory Validation
Ofqual's technical pilots on comparative judgment for standard-setting found "near-perfect alignment" with traditional standards and "negligible bias". This isn't unproven territory; it's been independently evaluated. - Transparent Reliability Reporting
Every RM Compare session publishes its reliability coefficient (typically 0.90+), misfit statistics, and audit trails. This isn't hidden in technical documentation; it's available to stakeholders, enabling genuine accountability. - Human-in-the-Loop Design
Comparative judgment keeps professional human judgment at the centre. It doesn't automate away expertise; it makes expertise transparent and aggregates it rigorously. - Ongoing Research Partnership
RM Assessment actively contributes to peer-reviewed research on comparative judgment validity, bias, and application across contexts. This grounds the approach in evidence, not just commercial advantage.
These aren't peripheral to RM Compare; they're central to its design philosophy. The product was built for exactly this moment: when institutions need to assess complex capabilities reliably and want to do so transparently.
A Progressive Path Forward
We don't need to wait for systemic collapse or crisis to act. Institutions can move forward now by:
- 1. Recognize the Washback Problem Explicitly: Acknowledge that current assessment methods are constraining curriculum innovation in ways that don't serve students' futures. Name it. Include it in curriculum conversations.
- Pilot Comparative Judgment in High-Value Contexts: Start with subjects/programmes where the washback problem is most acute:
- Humanities and extended writing (where reliability is lowest, but skills are highest-value)
- Creative and interdisciplinary work (where rubrics are most limiting)
- Authentic capstone projects (where assessment needs to capture complexity)
Use these pilots to demonstrate that comparative judgment produces reliable, defensible results for complex work. Build internal confidence.
- Gradually Expand Curriculum Scope: As reliability evidence accumulates, expand the curriculum scope of what's centrally assessed. Introduce more authentic, open-ended, collaborative work knowing it will be rigorously and fairly assessed.
- Watch the washback effects reverse: Teachers begin designing for deep learning rather than compliance, students develop authentic capability rather than test-taking skill, and curriculum aligns with what institutions claim to value.
- Share Learning and Co-Create Standards: Institutions adopting comparative judgment should publish findings, share lessons learned, and work collaboratively to develop sector standards. This is how positive change spreads, not through individual providers, but through collective professional movement.
The Bigger Picture: Assessment as Strategic Choice
Sherwood's article is right: when we know assessment is unreliable, when we know it's damaging learning, when we know solutions exist - institutions face a choice.
But the choice isn't just whether to "walk on by" problems we witness. It's a deeper choice about what role assessment plays in our educational systems.
Do we use assessment to constrain and control what students learn to what we can reliably measure? Or do we use assessment to enable and validate the complex, authentic learning that matters?
The first approach is easier in the short term: it feels rigorous, it's familiar, and the constraints are predictable. But it's increasingly indefensible in the age of AI, when the skills it measures are precisely those AI can automate.
The second approach is harder, but it's the only one that serves students' actual futures.
RM Assessment has spent years building the infrastructure to make this second choice possible: assessment methods that are rigorous and reliable without constraining what students can learn.
Invitation, Not Confrontation
We're not calling on institutions to "stop walking on by" in a spirit of accusation. Rather, we're inviting them to step forward into a more progressive vision of what assessment can enable.
The curriculum transformation everyone agrees is necessary is possible. But it requires rethinking assessment first. RM Compare exists to make that rethinking practical.
Is your institution is ready to explore how comparative judgment can?:
- Eliminate the washback constraints on curriculum innovation
- Achieve high reliability for complex, authentic work
- Enable the capabilities the AI era demands
- Build stakeholder trust through transparent, validated assessment
Let's talk about what positive washback could look like in your context.
The curriculum we need is already imagined. Assessment design is the piece that makes it real.
Related Reading
- Dennis Sherwood: "Walk on by: the dilemma of the blind eye" (SRHE Blog, December 2025)
- Curriculum change and the challenge of assessment backwash (RM Compare Blog)
- RM Compare as the Gold Standard Validation Layer (RM Compare Blog, October 2025)
- Restoring Trust in Meritocracy: How Organisations Are Fighting Back Against the Assessment Crisis (RM Compare Blog 3/3)
- Beyond Formula: The New Frontier for Assessment in an AI World (RM Compare Blog, July 2025)
