- Opinion
Why You See a Cup, but AI Sees Pixels: The "Amodal" Secret to Reliable Assessment

👉 How to use: Select your use case above. The generated prompt will instruct the AI to design an assessment strategy that leverages "Amodal Completion" (seeing the whole) rather than just "Modal" pixel-counting.
The Cat Behind the Fence
Look at the picture below. What do you see?.

If you are like every other human on the planet, you will say: “I see a cat standing behind a fence.” It feels like an obvious, almost trivial observation. But if we pause for a second and look strictly at the visual data hitting your retina, you are actually hallucinating.
Technically, you don't see a cat. You see vertical slices of orange fur separated by white wooden slats. You cannot see the cat's nose. You cannot see the curve of its back connecting to its tail. In a strict, data-driven sense, there is no evidence that these slices belong to a single, continuous animal. For all you know, those could be five separate fur-covered tubes standing in a row.
So, why are you so absolutely certain there is a whole cat there?
The answer lies in a cognitive superpower you use thousands of times a day without realizing it: Amodal Completion.
Your brain is a prediction engine, not just a camera. When it receives fragmented visual data (the slices), it instantly accesses your lifetime of experience - your "Tacit Knowledge" - to fill in the blanks. You know cats are solid objects. You know biology doesn't produce floating fur strips. So, your brain "completes" the image, drawing invisible lines to connect the pieces into a coherent whole.
You don't just see the pixels; you see the reality.
This might seem like a quirk of psychology, but it is actually the single most important difference between human intelligence and Artificial Intelligence. And when it comes to assessing complex work, whether it’s a student’s portfolio, a candidate’s CV, or an intricate piece of design, this ability to "see what isn't there" is the one thing AI cannot easily replicate.
The Science: The Visible vs. The Real
To understand why this matters for assessment, we need to distinguish between two types of perception: Modal and Amodal.
- Modal Completion is what happens when you see the explicit boundaries of an object. It is "What You See Is What You Get." If a line stops, the object stops.
- Amodal Completion is what happens when your brain perceives the whole object, even when parts of it are hidden. You see the "implied" edges. You know the cat continues behind the fence because your internal model of the world understands biology, physics, and object permanence.
Here is the catch: Current AI models are largely stuck in the "Modal" world.
When a standard Computer Vision model looks at that cat behind the fence, it struggles to connect the dots. It sees ten vertical strips of fur. It might statistically guess that "fur usually equals cat," but it doesn't understand the physical reality of the animal. It is just counting pixels.
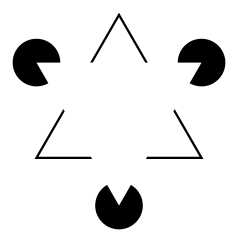
To prove your brain is doing something superior, look at this famous illusion, known as the Kanizsa Triangle:
Do you see the bright white triangle in the center? Look closer. It doesn't actually exist.
Your brain invented those white lines to make sense of the black 'Pac-Man' shapes. This is Amodal Completion in action.
The Application: Why This Matters for Assessment
You might be thinking, "I assess essays and portfolios, not optical illusions."
But the process is exactly the same. When you assess a student's coursework or a candidate's CV, you never see the "whole" picture. You only ever see fragments. A paragraph here, a sketch there, a list of previous job titles. These are your "Pac-Man" shapes.
- The AI View (Modal): An AI reads the essay and checks the grammar (the visible pixels). If the sentences are complex, it gives a high score. It cannot see what is missing.
- The Human View (Amodal): You read the same essay and immediately sense the intent behind it. You spot the hesitation in the argument. You realise the student has grasped the core concept, even if their spelling is poor.
You aren't just grading the text on the page; you are using the text to construct a mental model of the student's capability. You are filling in the gaps to judge the reality behind the artifact. AI measures the fragments; you measure the whole.
The Problem: The "Modal" Trap of AI
This distinction between seeing pixels and seeing reality explains why AI struggles so profoundly with complex assessment.
Generative AI (like ChatGPT or Midjourney) is essentially a very advanced guessing machine. It looks at the visible pixels (or words) and calculates the statistical probability of what should come next. It is excellent at mimicking patterns, but it is terrible at understanding consistency.
The "Impossible Object" Test Imagine a student submits a design for a sculpture that looks like the shape right.

- The AI Assessor: It scans the image. It identifies "corners," "shading," and "triangle shapes." It checks its database and concludes: "This is a 3D triangle." It accepts the geometry because it is looking at the local features (the modal data), not the global logic.
- The Human Assessor: You look at the same image and your brain’s "physics engine" kicks in immediately. You spot the contradiction. You know that in 3D space, those corners cannot connect that way. You aren't just judging the lines; you are simulating the object in your mind and realizing it cannot exist.
The "Polished Essay" Trap This trap is even more dangerous in text assessment.
- The AI: Reads a student essay. The grammar is flawless. The vocabulary is sophisticated. The structure follows the "Introduction-Body-Conclusion" format perfectly. The AI awards an 'A' because the visible pixels (the text) are perfect.
- The Human: You read the same essay. You notice the arguments don't quite connect. You sense a lack of specific examples. You realize the "voice" shifts halfway through. Your brain amodally completes the "student's understanding" and realises: They don't actually know what they are talking about. They just used a thesaurus—or ChatGPT.
AI measures the mask. Humans see the face behind it.
The Solution: Why RM Compare Works
This is why Adaptive Comparative Judgement (ACJ), the engine behind RM Compare, is such a powerful defense in the age of AI.
Traditional marking (using rubrics) tries to force humans to act like robots. It asks you to look at the "visible pixels" - Did they use 3 quotes? Is the introduction 5 lines long? - and assign a score based on a checklist. This reduces your complex human perception down to a "Modal" algorithm.
RM Compare does the opposite.
By showing you two pieces of work and simply asking, "Which is better?", we are unlocking your brain’s natural ability to process the whole picture. We are asking you to perform Amodal Completion.
- You don't just check if the sculpture is smooth; you judge if it has intent.
- You don't just check if the code runs; you judge if the logic is elegant.
- You don't just check the CV for keywords; you judge the capability.
This changes the meaning of reliability. When five different judges look at a piece of work in RM Compare and agree on its rank, they aren't just agreeing on the surface-level features. They are reaching a consensus on the hidden reality of that student's potential. They are using their shared "Tacit Knowledge" to see the cat behind the fence, even when the view is blocked.
Conclusion: Trust Your Brain
We often hear that human judgement is "subjective" and therefore "unreliable."
Cognitive science proves the opposite. That "subjectivity" is actually a highly advanced simulation engine that has been refined over 200,000 years of evolution. It allows you to spot a fake, sense potential, and understand context in a way that no current AI model can match.
So, if your brain is this good at filling in the gaps - at seeing the whole cat even when it's hidden - does that mean you need perfect, high-resolution scans of every exam paper? Or could you get the same reliable results from a "messy" photo taken on a smartphone?
In Part 2 of this series, we’ll explore the myth of the "Perfect Photo" and how your brain’s ability to filter noise is the key to faster, fairer assessment.