- Opinion
Beyond the Black Box: Why Ofqual’s AI Principles are a Gift to Assessment Innovation

The publication of Ofqual’s Principles of AI Use in Marking brings some welcome guardrails to a landscape that, until recently, felt a bit like the "Wild West". For those of us in the assessment sector, the sudden explosion of AI capabilities felt both exhilarating and at times lawless.
Ofqual has now set the boundary: AI cannot be the sole marker in high-stakes assessments. Far from a setback, this is a call to maturity. It marks the transition from "can we do this?" to "how might we do this responsibly?".
The "Black Box" Dilemma
The central challenge of AI in marking is transparency. Even the most advanced AI struggles to explain why it awarded a specific grade in a way that satisfies a regulatory appeal. In high-stakes education, "because the algorithm said so" is not a defensible answer.
At RM Assessment, we continue to consider on how to balance the efficiency of our AI marking engine, with the human-centered requirements described by Ofqual. We don’t believe the goal is to replace humans, but rather to find where technology can best support human expertise.
How might RM Compare help?
The RM Compare team are exploring a hybrid approach where technology and human judgment validate one another. Instead of a rigid system, we see a collaborative workflow:
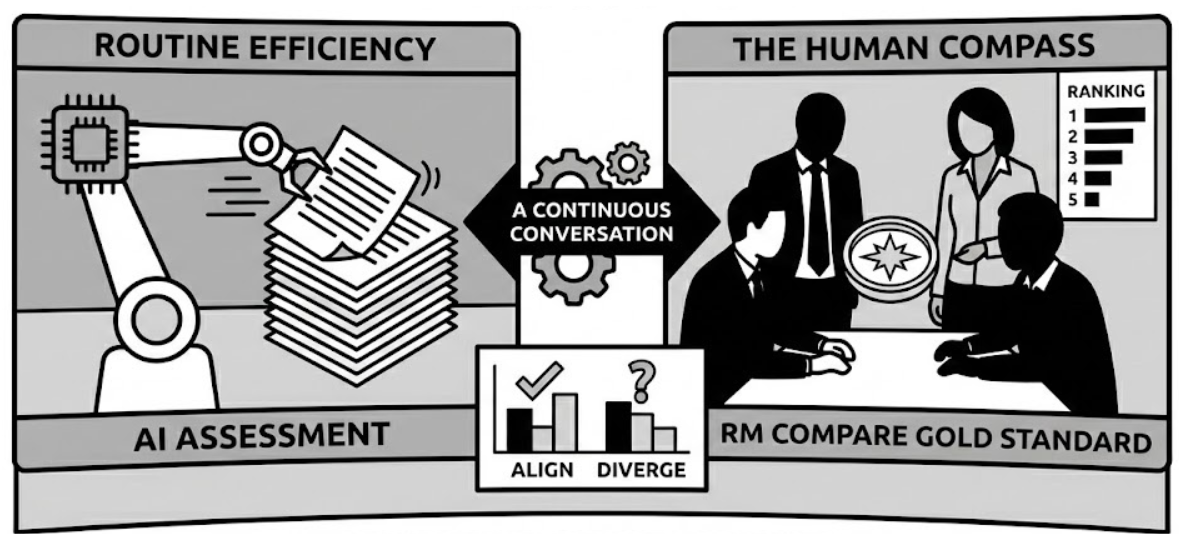
- Routine Efficiency: AI Assessment engines can process the bulk of responses, handling routine judgments at scale to free up expert time.
- The Human Compass: RM Compare (Adaptive Comparative Judgment) uses the collective wisdom of expert markers to create a "Gold Standard" rank order on a sample of work.
- A Continuous Conversation: By comparing the AI’s marks against this human consensus, we can see exactly where the two align and, more importantly, where they diverge.
We have written extensively in the past about how RM Compare might be used as a AI Validation Layer.
Building Transparency Together
The most important part of this process isn't the technology, it’s the Validation. This approach allows awarding organizations to say with confidence: "The AI aligns with our expert judges 87% of the time; here is the evidence of how we managed the remaining 13%."
This creates the human-readable audit trail that Ofqual’s principles demand. Comparative judgment is particularly helpful here because humans are remarkably consistent at comparing two pieces of work, even when assigning an absolute score to a single piece feels difficult.
A Shared Journey
Public trust is the only true currency in assessment. We recognise that no one has all the answers yet, and Ofqual’s paper is a helpful map for the journey ahead. The future isn't AI or human judgment; it’s about how we intelligently - and humbly - combine them to build a better system for every student.