- Research
From Product to Process: How VFWA and RM Compare might reclaim academic integrity in the age of AI
Generative AI has broken one of higher education’s quiet assumptions: that a polished essay is a reliable proxy for student thinking. When tools can generate fluent academic prose on demand, we can no longer treat the final product as straightforward evidence of cognitive effort or authorship.
The question for universities is no longer, “How can we prove this text wasn’t written by AI?” but “How can we design assessments where AI cannot replace the student’s contribution, only support it?”
Rather than escalating an arms race of AI detection, a better response is to redesign assessment around process. That’s exactly what Kelly Webb‑Davies’ Voice‑First Written Assessment (VFWA) model proposes, and what RM Compare can operationalise in practice.
The problem with product‑only assessment
Traditional written assessment tends to reward Academic English. Students who sound like insiders are often credited with stronger thinking, while those who are neurodivergent, have English as an additional language, or come from non‑traditional backgrounds pay a “linguistic tax” even when their reasoning is strong.
AI amplifies this distortion. If all we see is a final PDF, we can’t easily distinguish between a student’s own developing argument, and a model’s highly polished, statistically plausible text.
We need to stop treating the product as a proxy for the process.
VFWA in a nutshell: secure thinking first, polish later
VFWA offers a simple but powerful structural shift:
- Stage 1 – Secure Baseline (Voice‑First)
Under observed, AI‑free conditions, students respond to an unseen task in whatever modality best captures their thinking: speech, sketches, bullet points, informal writing. The goal is to record the “thinking signal”, not to produce a perfect essay. - Stage 2 – Refinement (Tools Allowed)
Students then take that Stage‑1 evidence and professionalise it into a polished product, using any appropriate tools including AI. What’s assessed is their evaluative judgement: how well they refine, extend, check, and communicate their own ideas.
This preserves intellectual sovereignty (the ideas start with the student) and increases equity (students choose the voice and mode that work for them), while still embracing realistic tool use.
How RM Compare makes VFWA workable
VFWA is a compelling blueprint, but it needs infrastructure. RM Compare provides three crucial capabilities:
- Modality‑agnostic comparison
RM Compare’s Adaptive Comparative Judgement (ACJ) lets judges compare any two artefacts (for example audio, video, image, sketch, text) by answering a single holistic question such as:
“Which artefact shows stronger reasoning in response to this task?”
That makes Stage‑1 reasoning comparable even when formats differ. - Learning by Evaluating (LbE)
Students can act as contributing judges in Stage 1, comparing peers’ work and justifying their decisions. This “learning by evaluating” phase helps them internalise what good reasoning looks like before they refine their own work, and generates a rich heap of feedback for everyone. - Scalable, defensible judgement in Stage 2
In Stage 2, refined products are uploaded to RM Compare for a summative ACJ session, judged by a context‑appropriate pool (staff only, or staff plus trained student assessors). The outcome is a reliable rank and scale that can be mapped to grades, with exemplars and comments available for teaching and moderation.
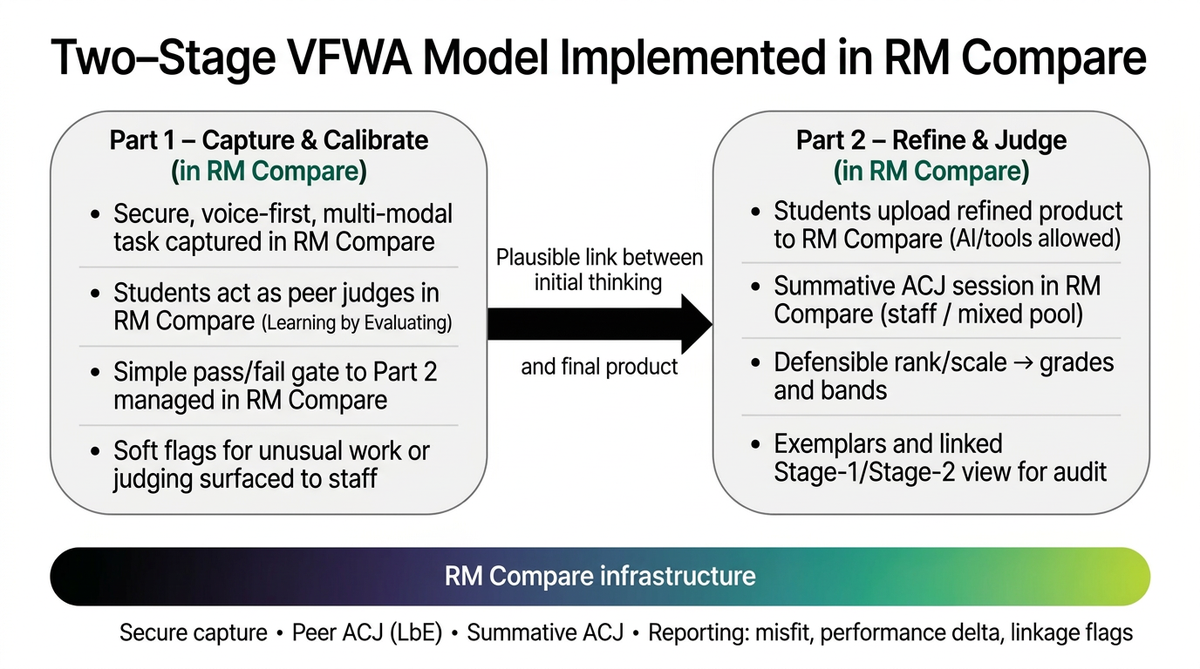
A simple two‑stage pattern
In practice, the model looks like this:
- Part 1 – Capture & Calibrate (in RM Compare)
- Secure, voice‑first, multi‑modal task
- Short peer‑judging round (Learning by Evaluating)
- Simple pass/fail gate into Part 2 based on participation and engagement
- Soft flags for unusual work or judging behaviour, for staff awareness
- Part 2 – Refine & Judge (in RM Compare)
- Students independently refine their work with tools (AI permitted)
- Final artefacts judged via ACJ in RM Compare
- Defensible scale → grades, bands, and exemplars
Instead of trying to “catch AI” in the finished essay, staff look at the evolution of the work: does the polished submission make sense as a development of the student’s own Stage‑1 thinking?
From AI policing to process‑based trust
This two‑stage VFWA + RM Compare model does three things that matter to institutions right now:
- It protects integrity by securing the origin of ideas and giving staff an auditable link between process and product.
- It improves learning by using peer comparison (LbE) to build evaluative judgement, not just grades.
- It supports equity by allowing students to show their thinking in ways that fit their linguistic and cognitive profile, before the demands of academic prose kick in.
The question for universities is no longer, “How can we prove this text wasn’t written by AI?” but “How can we design assessments where AI cannot replace the student’s contribution, only support it?”
VFWA gives us the pedagogy. RM Compare provides the engine.