- AI Validation
If AI Is Serious About Learning Outcomes, ‘Ground Truth’ Has to Mean More Than Last Year’s Exam Scores (Part 2/2)

In Part 1 of this series, we asked who gets to define “learning” in an AI world and argued for a human‑grounded validity layer alongside AI‑native analytics. That conversation becomes very concrete when you look at one small, easy‑to‑miss element in OpenAI’s Learning Outcomes Measurement Suite diagram: the bubble labelled- “partner‑provided ground truth (exam scores, classroom observations, attendance, etc.)”.
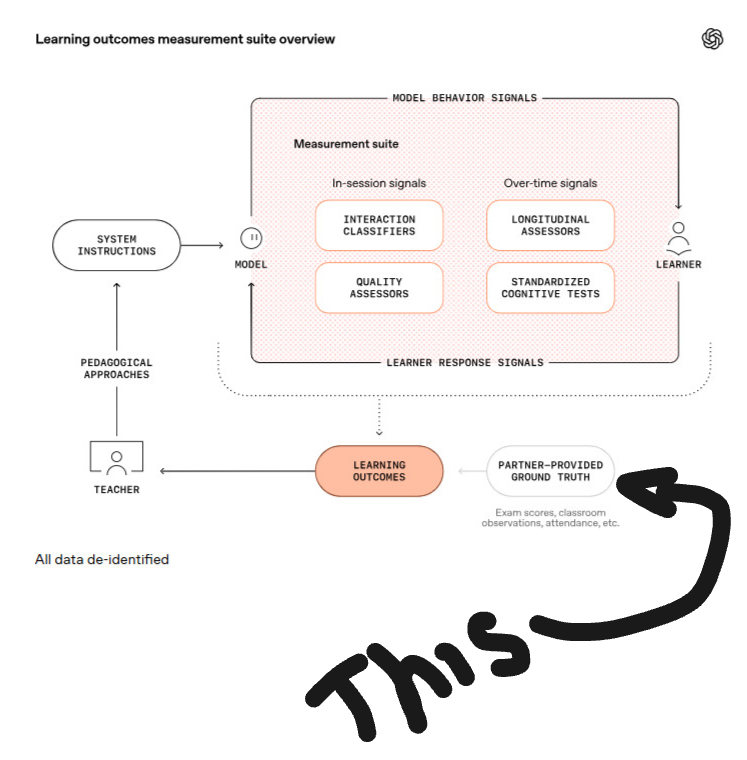
Original Image source: https://openai.com/index/understanding-ai-and-learning-outcomes/
Everything else in the picture is generated inside the AI environment. Models are steered by system instructions. Classifiers and assessors interpret what happens in a session. Longitudinal engines track usage and performance over time. Standardised tests provide familiar anchors. Together, these components create a powerful, AI‑centred narrative about learning.
Yet even in this architecture, there is an admission that the story is incomplete without something from outside the system: evidence that partners bring to the table. The question is whether we are satisfied with filling that box with last year’s exams and registers – or whether we want something better.
The Ceiling Set by Legacy Metrics
The examples currently attached to “partner‑provided ground truth” will be familiar to anyone in education:
- Exam scores
- Classroom observations
- Attendance
They are the measures we have used for decades. They also come with well‑known limitations.
Exam scores tell us how well students performed on a particular paper, on a particular day, under particular constraints. They struggle to capture the richness of extended projects, collaborative work, or creative problem‑solving. Observations can surface valuable insights about engagement and behaviour, but they are patchy, labour‑intensive and difficult to standardise across classes and contexts. Attendance tells us who showed up, not what they learned.
If we treat these as the natural ceiling of “ground truth”, we implicitly ask AI systems to do one thing above all: become very good at predicting and optimising those legacy metrics. The risk is that we end up with highly sophisticated tools that can nudge exam performance or attendance figures, while leaving untouched many of the deeper capabilities we say we care about.
If AI in education is genuinely about learning outcomes, that box needs to hold more ambitious evidence.
A Different Kind of Ground Truth
Adaptive Comparative Judgement (ACJ), as implemented in RM Compare, offers a different class of signal for that partner‑provided space.
Rather than starting from test items or behaviour codes, ACJ begins with authentic work: essays, portfolios, lab reports, design artefacts, performances, oracy tasks, creative writing, engineering prototypes. These are the forms in which learning most recognisably shows up in the world.
In an ACJ session, pairs of such artefacts are presented to expert judges. For each pair, a judge decides which is better overall. The process is repeated many times, across many judges, guided by an adaptive algorithm that focuses comparisons where they are most informative. Out of these simple choices emerges a stable rank order of work quality.
What makes this powerful as “ground truth” is not just the ranking itself, but what it encodes:
- It captures the tacit professional standards that experienced teachers, examiners and practitioners actually apply in their disciplines.
- It surfaces differences in depth, originality, coherence and fitness for purpose that are difficult to reduce to item‑level scores.
- It produces exemplars at different levels of quality that can be used to make expectations transparent for both teachers and learners.
This is evidence about what students can produce when asked to tackle complex tasks, not just how they performed on constrained tests or how often they logged in.
Plugging ACJ Into the AI Measurement Loop
So how does this relate back to an AI‑first measurement suite?
Imagine an institution that has adopted AI‑enabled tutoring and content tools. Over time, the system builds up a rich view of learners’ interactions: which hints they use, how they revise drafts, how often they return to a topic, which problem‑solving paths they follow. Models interpret these traces as signals of engagement, persistence, critical thinking and more.
From this, the AI side generates hypotheses:
- This pattern of support appears to foster deeper reasoning.
- That configuration of feedback seems to keep students productively engaged for longer.
- Certain prompt designs correlate with more creative solutions.
These are valuable insights – but they are still, fundamentally, claims about what is happening.
Now introduce ACJ as the partner‑provided ground truth. At key points – the end of a module, a capstone project, a cross‑cohort comparison – the institution runs RM Compare sessions on artefacts produced under different AI conditions. Judges are blind to who used what. They simply compare the work and decide which is better.
If the system’s critical‑thinking or creativity metrics are telling a true story, those gains should be visible in the comparative judgements. Work from the “better” AI conditions should rise in the rank order. If the ACJ results show no meaningful difference, or even favour the supposedly “less supported” group, then something important has been revealed about the limits or side‑effects of the AI configuration.

In this way, ACJ functions as a model‑agnostic validity layer. It does not compete with AI analytics; it tests and grounds them in independent human judgement of complex work.
From Afterthought to Anchor
Reframing ACJ as ground truth changes the role of that small bubble at the bottom of the diagram.
Rather than being an afterthought – a place to park whatever data a system happens to have – it becomes the anchor that holds the entire measurement suite accountable to the real world of student work and professional standards.
Institutions that adopt ACJ are not just sending in exam files and attendance spreadsheets. They are contributing:
- Large‑scale, high‑reliability judgements of authentic artefacts.
- Evolving discipline‑specific standards, expressed through the decisions of expert communities.
- Rich exemplars and narratives about what different levels of quality actually look like.
When that kind of evidence feeds into the partner‑provided bubble, the relationship between AI vendors and education systems subtly shifts. The system is no longer just a supplier of users and legacy data; it becomes a co‑author of the definition of learning itself.
Raising Our Expectations of Ground Truth
The phrase “ground truth” carries weight in AI research. It is supposed to mean the thing we trust most – the reference point against which models are trained, calibrated and judged.
In education, we should be wary of letting convenience or habit define that ground truth for us. If we accept only last year’s exam scores and registers, we should not be surprised if our AI tools become very good at improving exactly those numbers, and not much more.
If, instead, we invest in richer forms of evidence – like the comparative judgements generated through RM Compare – we raise our expectations of what AI should be accountable to. We ask systems not just to boost engagement metrics, but to support the production of work that stands up to scrutiny from informed human judges.
In that future, AI‑native measurement suites and Adaptive Comparative Judgement are not rivals. One offers scale, speed and process‑level insight. The other offers deep, artefact‑based evidence of what learners can actually do. Together, they give us a more honest and more ambitious answer to the question that matters most:
Are our students really learning the things we value – and how do we know?
If your institution is exploring AI in teaching and learning and you want your “ground truth” to reflect more than last year’s exams, RM Compare can help you build that human‑grounded validity layer.
