- Product
Is your software high quality, how do you know – and does it matter?

When important decisions, results or reputations depend on a piece of software, “quality” stops being a nice‑to‑have. It becomes the question of whether that system will be there when people need it, and whether it can adapt as your needs change. That might be national exams, professional licensing, large‑scale school projects, or internal evaluations that shape careers and investment.
People often talk about quality in terms of bugs, performance and security. Those matter, but they are not the fundamental test. As Dave Farley argues, the real mark of high‑quality software is how easily and safely you can change it. If you can change your system quickly, you can improve everything else. If you cannot, quality leaks away over time, no matter how good things look today.
Quality, in other words, is your ability to respond to what you learn. New regulations, new assessment models, new stakeholder expectations or new research findings only create value if your systems can adapt without drama. A platform that feels “stable” but is hard to change will eventually hold your organisation back, whether you are running external qualifications, professional development, or large‑scale improvement work.
From opinion to evidence with DORA
“Ability to change” sounds right, but how do you know if you actually have it? The DevOps Research and Assessment (DORA) work answers that by defining four key metrics: how often you deploy software, how long it takes a change to reach production, how frequently changes cause problems, and how quickly you recover when something goes wrong. Over more than a decade and roughly 45,000 professionals, they use these measures to group teams into Low, Medium, High and Elite performers. The measures are used and trusted by many of the worlds leading organisations and is run by Google Cloud.
The 2025 DORA State of AI‑Assisted Software Development report shows where the industry really is. Only 16.2% of teams say they deploy on demand, multiple times per day; more than half deploy less than once a week. Only 9.4% can get a change from code committed to production in under an hour, and 43.5% take more than a week. Just 8.5% report a change‑failure rate below 2%, while over a third see more than 16% of changes cause incidents. Only 21.3% of teams can restore service from a failed deployment in under an hour; more than a third take longer than a day.
DORA also clusters teams into seven archetypes. The two best‑performing groups – “Pragmatic performers” and “Harmonious high‑achievers” – together represent just under 40% of the sample and manage to combine high throughput with low instability, showing that speed and stability can coexist. The remaining 60% compromise on one or both dimensions. High and Elite performers are not just faster for the sake of it; they are more reliable and more successful at hitting their wider organisational goals.
For any buyer evaluating software, the message is simple: teams that can change their software quickly and safely are the ones least likely to let you down when it matters.
Where RM Compare sits
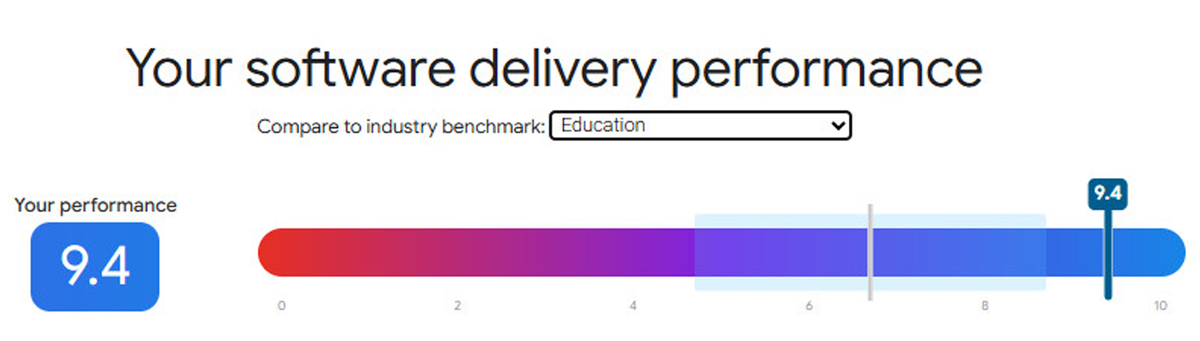
Against that backdrop, it is worth being specific about how RM Compare performs.
In the latest DORA quick check for our primary RM Compare service, the overall software delivery performance score was 9.4 out of 10, with an “Elite” rating against the education benchmark. That reflects several concrete behaviours. Lead time for changes is less than one day, so approved changes move from commit to production within a working day instead of queuing for the next big release. Deployments happen on demand, multiple times per day, not on a weekly or monthly rhythm. The change‑failure rate is minimal, noticeably better than many teams reporting double‑digit failure rates in the DORA distributions. And when something does go wrong, failed deployments are recovered in under an hour, placing RM Compare in the fastest‑recovering slice of teams globally.
The same quick check also assesses three underlying capabilities. RM Compare scores 9.4/10 for Continuous Integration, and a full 10/10 for both Loosely Coupled Teams and Generative Organisational Culture. In practice, that means small, safe changes flowing through automated pipelines; teams able to deploy independently rather than waiting on others; and a culture where information flows, problems are surfaced early and failures are treated as opportunities to improve. These are exactly the conditions that DORA research links to high and elite levels of performance.
Why this matters to buyers of RM Compare
Whether you are an assessment director, a CIO, a programme lead or a school group making a decision, these engineering details translate into practical benefits.
Fast, reliable delivery means you can evolve your programmes without being tied to a vendor’s annual release cycle. When qualification structures change, professional standards are updated, or new research suggests a better way to run Adaptive Comparative Judgement, RM Compare can support those changes within the planning horizon you are already working to. The platform keeps pace with your thinking, rather than forcing your thinking to fit the platform.
Low change‑failure rates and fast recovery reduce the risk that technical issues will surface during important windows – exam periods, judging sessions, major internal reviews, or public reporting deadlines. If an issue does occur around a deployment, it is handled quickly rather than turning into an extended outage. That protects candidate and participant experience, reduces operational stress, and helps you meet the expectations of stakeholders and regulators.
Over time, a platform that is easy to change avoids the build‑up of workarounds and fragile processes that often appear in systems which are hard to modify. By engineering RM Compare for frequent, safe change and operating in the high/elite DORA bands rather than the industry average, the intention is to give organisations a product that grows with their ambitions instead of constraining them.
So the question is not just “Is this platform high quality?” A sharper question is: how easily can it change when what you need from it changes? Our view of quality is built around answering “very easily, and very safely” to that question.