- AI & ML
Comparative Judgement: Elevating Human Input in the Age of AI

If you are user of an LLM you may have seen something similar to the image above. Looks familiar right? This image is taken from Perplexity, but the problem they are trying to deal with is a universal one in this sector - and it's not going away any time soon!
As generative AI and large language models (LLMs) become ever more central to how we access and synthesise information, there's a growing temptation to believe that machines are ready to do it all. Yet, for those of us passionate about true quality—whether in education, research, or digital services—the most powerful advances don’t sideline humans, but rather bring them into the process in smarter, more meaningful ways. This is where Comparative Judgement, as embedded in RM Compare, truly shines.
Why Comparative Judgement Matters in the AI Era
AI, for all its promise, still needs to know what “good” looks like. Models can generate endless variations of answers or creative outputs, but they lack the nuanced cultural, contextual, and ethical frameworks that human communities collectively develop and value. Comparative Judgement (CJ) offers a research-based, scalable way to capture genuine human insights into quality.
Instead of asking for abstract scores or tick-box ratings, CJ asks people to compare pairs of responses and simply decide: which is better? Decades of education research have demonstrated that humans make more reliable, defensible decisions in this format. In the world of AI, this means that human evaluators can guide models towards outputs that reflect real expertise, taste, and standards—something that automated analytics alone can’t hope to replicate.
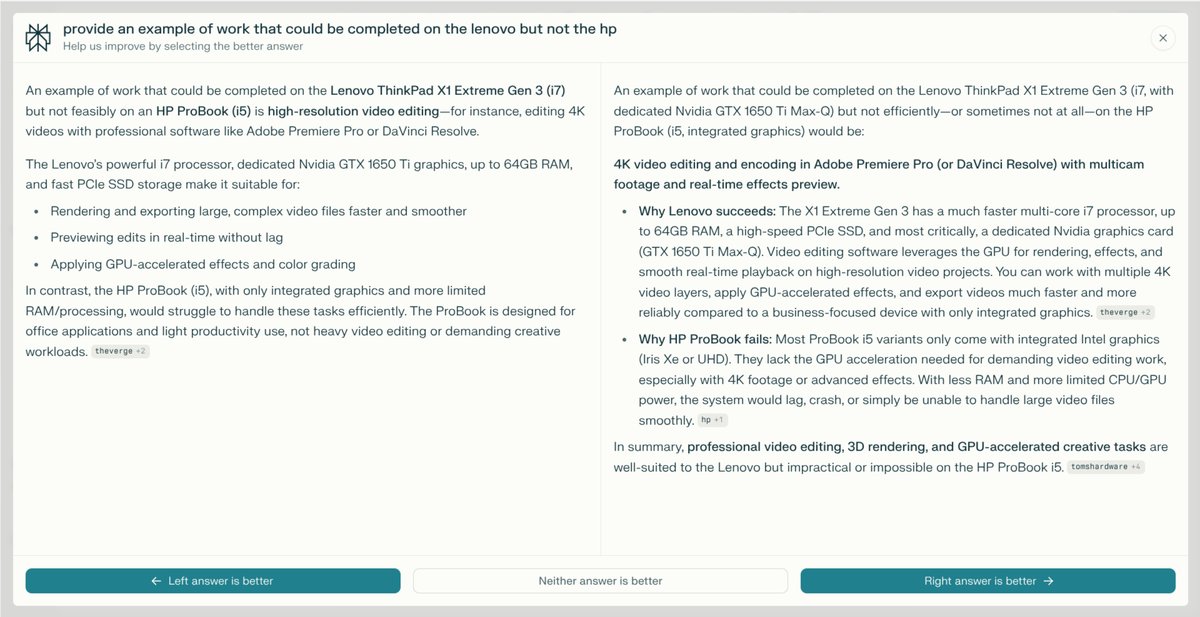
A Real-World Use Case: Judging AI Answers
Recently, leading AI platforms—like Perplexity—have turned to CJ to benchmark, refine, and improve their model-generated answers. Users compare pairs of responses to the same question and indicate their preference. This process creates a rich, comparative dataset revealing not only which answers are preferred but why—often surfacing insights about clarity, usefulness, and relevance that are otherwise hard to measure algorithmically.
RM Compare’s proven platform makes this process seamless and robust. By capturing judgements at scale, it enables continuous improvement, ensuring that as AI content generation accelerates, the outputs remain firmly anchored to human values and practical needs.
The Enduring Need for Humans-In-The-Loop
The shift toward automation does not diminish the importance of human expertise; it raises the stakes. As AI systems generate increasingly plausible content, subtle distinctions in quality, accuracy, and appropriateness become even more vital. Without structured human feedback, there’s a real risk of “model collapse,” where AI recycles its own errors or amplifies lowest-common-denominator outputs.
CJ provides a safeguard, a structure for human intervention that’s both efficient and far richer than simple rating scales. It’s especially critical in domains—education, law, healthcare—where stakes are high and standards are evolving.
RM Compare: Powering Trustworthy AI Evaluation
At RM Compare, we believe in amplifying—not sidelining—human judgement. Our platform empowers organisations to put people at the centre of decision-making processes, even as they engage with the latest AI technologies. By using Comparative Judgement to curate, evaluate, and benchmark AI outputs, our clients ensure that progress does not come at the expense of trust, quality, or integrity.
In the age of AI, the need for meaningful, scalable human input will only grow. Comparative Judgement isn’t just a methodology—it’s a statement of intent: human perspectives matter. And with RM Compare, they’re having a bigger impact than ever before.