- AI Validation
Fairness in Focus: The AI Validation Layer Proof of Concept Powered by RM Compare
👉 How to use: Select your use case above. The generated prompt will instruct the AI to design a "Human-in-the-Loop" validation strategy that links back to this proof of concept.
In today’s rapidly changing educational landscape, the key challenge isn’t just whether AI can mark student work, but how to ensure every mark is reliably fair. With that mission in mind, our latest proof of concept was designed to demonstrate why RM Compare is uniquely positioned as the foundation for trustworthy, scalable automated assessment.
This is the Fourth in a short series of blogs exploring the discrepancy between how AI and Humans approach assessment. There is an accompanying White Paper (Beyond Human Moderation: The Case for Automated AI Validation in Educational Assessment) that goes into even more detail.
Why RM Compare Matters
Automated validation relies entirely on the idea of a trusted “gold standard”—a set of marks, established by expert consensus, against which AI decisions can be compared and continuously calibrated. RM Compare is the ideal platform for this purpose. Its adaptive comparative judgement (ACJ) system gathers input from multiple expert markers, using sophisticated pairing and ranking to reach a defensible, consensus-based standard for every item—whether short answer, essay, artwork, or creative task.
By drawing on this technology, our POC ensures that the reference set for AI validation is not a single opinion or static rubric, but a rigorously established expert consensus. This professional consensus ranking is the “keystone”—it anchors fairness, accuracy, and accountability for every subsequent automated decision, providing confidence for all users.
Read the full White Paper: Beyond Human Moderation: The Case for Automated AI Validation in Educational Assessment
Our Validation Process—Powered by RM Compare
We wanted to make the process transparent and accessible, so here’s how it works at a high level:
Calibration
First, AI marks a set of training items. These scores are compared to the RM Compare gold standard, which was generated via comparative judgement across a team of expert educators. Any discrepancies are flagged and analyzed, then AI parameters are adjusted. The cycle repeats until machine scores closely match the gold standard—a process you can see in the calibration diagram below:
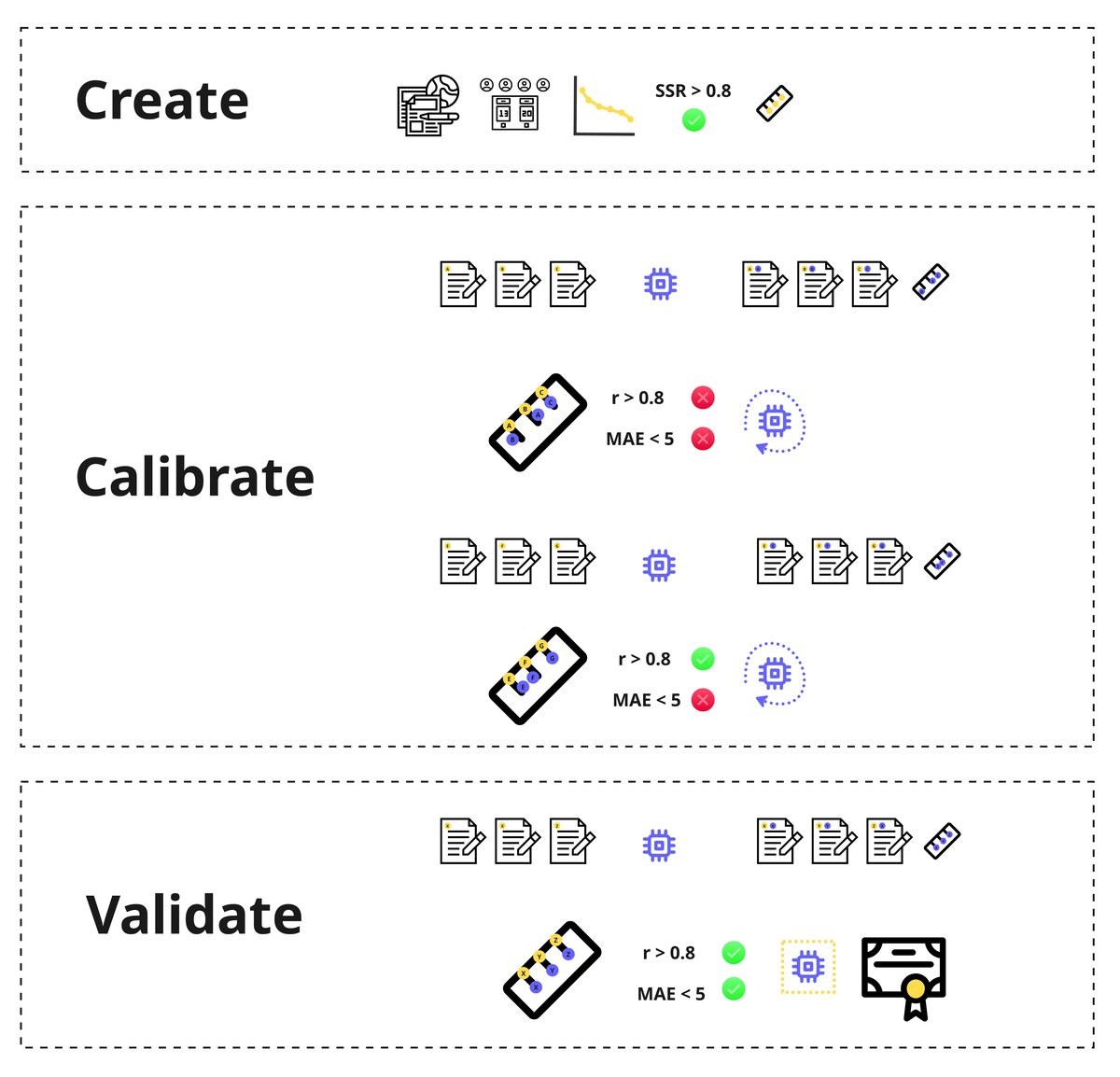
Validation in Action
With calibration achieved, each new batch of assessments follows the validation journey. If the AI’s mark aligns with the gold standard, the score is awarded automatically (successful validation). When a discrepancy surfaces, that script is routed for human review and the insights are also used to further refine the model. This ensures that no “difficult to score” item is lost or ignored—the system learns and improves each time.
Demonstrating Success—Visual Proof
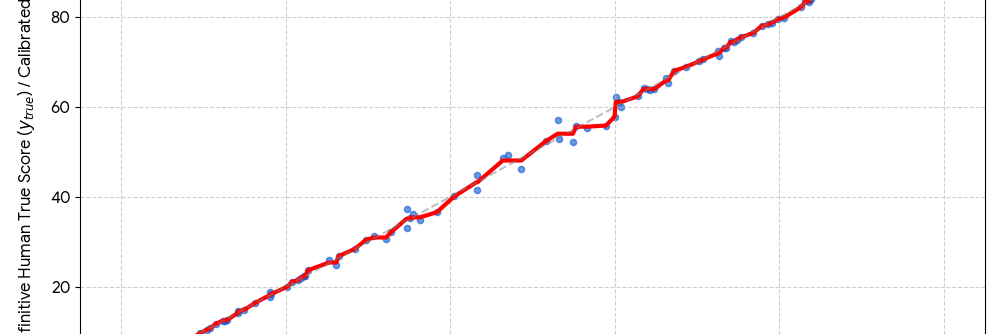
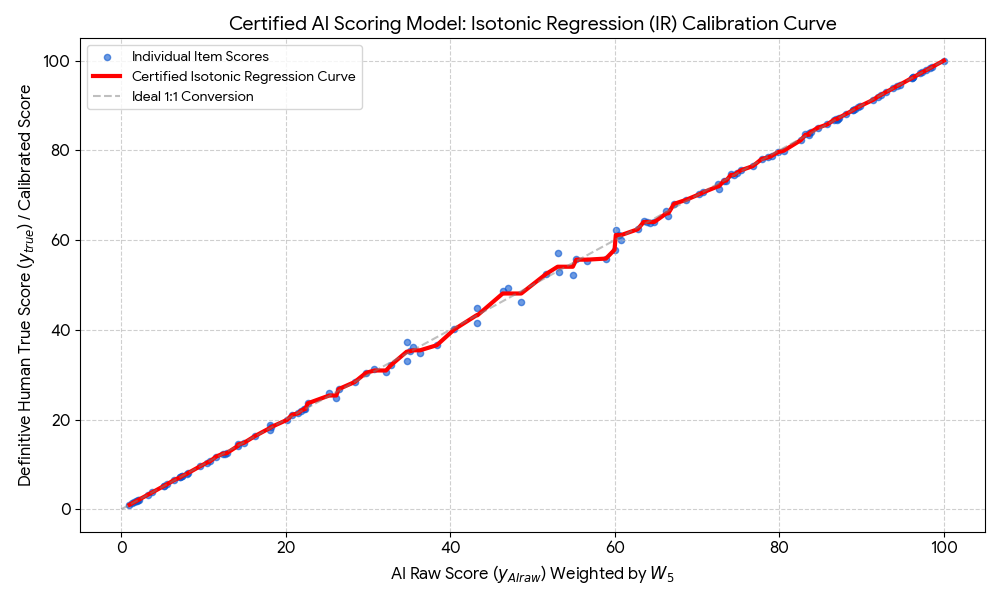
The test of a robust calibration is in the results. The chart below shows what a successful output looks like: blue dots are individual scripts, the red line is the AI’s calibrated scoring curve, and the proximity to the grey 1:1 line is direct evidence of fairness and fidelity to expert standards.
What Makes RM Compare the Keystone?
- Defensible, Representative Benchmarking: RM Compare delivers a gold standard based on collective expert judgement, not just static rules or single opinions.
- Scalability by Design: Its ACJ process is built for consistency—whether you need a reference set for 10, 100, or 10,000+ students.
- True Continuous Improvement: The system isn’t frozen. Any new, challenging script helps refine the gold standard, improving fairness over time.
Looking Ahead
This POC is early proof that integrating RM Compare into automated assessment provides the confidence educational AI marking needs—anchoring every automated result with a transparent, consensus-driven benchmark.
Want to learn more, contribute, or see a demonstration? We welcome educators, examiners, and policymakers to engage with us as we help shape the next era of fair and scalable assessment.
The blog series in full
- Introduction: Blog Series Introduction: Can We Trust AI to Understand Value and Quality?
- Blog 1: Why the Discrepancy Between Human and AI Assessment Matters—and Must Be Addressed
- Blog 2: Variation in LLM perception on value and quality.
- Blog 3: Who is Assessing the AI that is Assessing Students?
- Blog 4: Building Trust: From “Ranks to Rulers” to On-Demand Marking
- Blog 5: Fairness in Focus: The AI Validation Layer Proof of Concept Powered by RM Compare
- Blog 6: RM Compare as the Gold Standard Validation Layer: The Research Behind Trust in AI Marking