- Opinion
A trip to the dentist
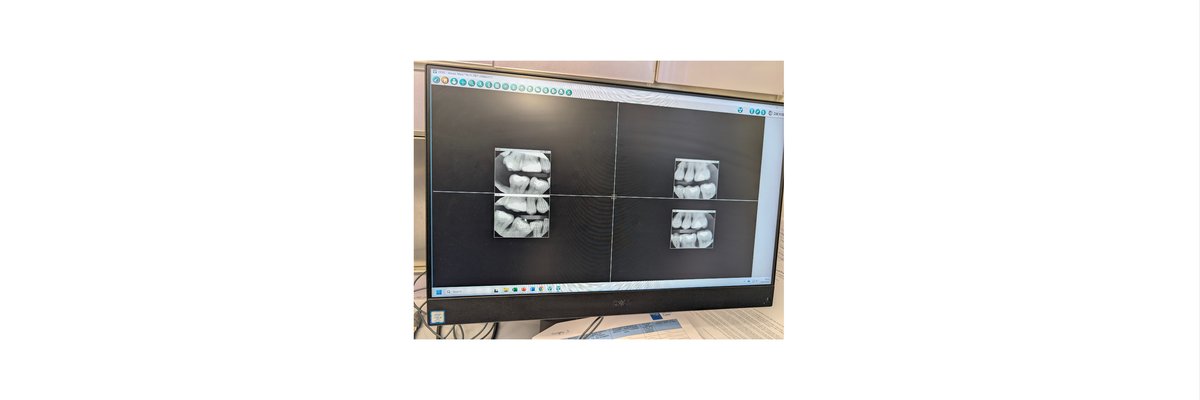
This morning I went for a routine dental check‑up.
On the monitor in front of us were four bitewing X‑rays: the images taken that morning on the left, and the same teeth from two years ago on the right. My dentist didn’t show me any scores, risk percentages or traffic‑light overlays. He simply flicked between the images, zoomed in and out, and sat in silence for a few seconds.
Then he said, almost casually, “Overall, this picture looks a little better than that one. You’ve improved here, stayed stable here, and there’s one area we need to watch.”
As a patient, that single judgement will influence what I do next: whether I accept treatment, how carefully I brush, whether I actually keep the follow‑up appointment. As a product manager working on RM Compare, it felt like a live demonstration of everything we talk about when we talk about comparative judgement, amodal completion and trust.
A dentist doing comparative judgement
What struck me was how naturally my dentist fell into a comparative frame. He wasn’t mentally ticking boxes on a rubric. He was looking at two artefacts and asking, “Which represents a healthier, more stable situation?”
He compared bone levels, the contours of fillings, the shadows around contact points. He weighed small regressions against small improvements and, from that messy set of impressions, arrived at a single holistic judgement: better, worse, or broadly the same.
This is exactly what Adaptive Comparative Judgement does with student work. We don’t ask experts to assign numbers in isolation; we ask them to compare two pieces and choose the better one, given the construct they care about. The reliability emerges from those repeated, context‑rich comparisons.
Watching him, I could almost see an RM Compare interface wrapped around the X‑rays: “Bitewing, April 2026” on one side, “Bitewing, April 2024” on the other, and a simple question: which image better represents oral health?
The screenshot below is from this morning. The layout looks familiar right?
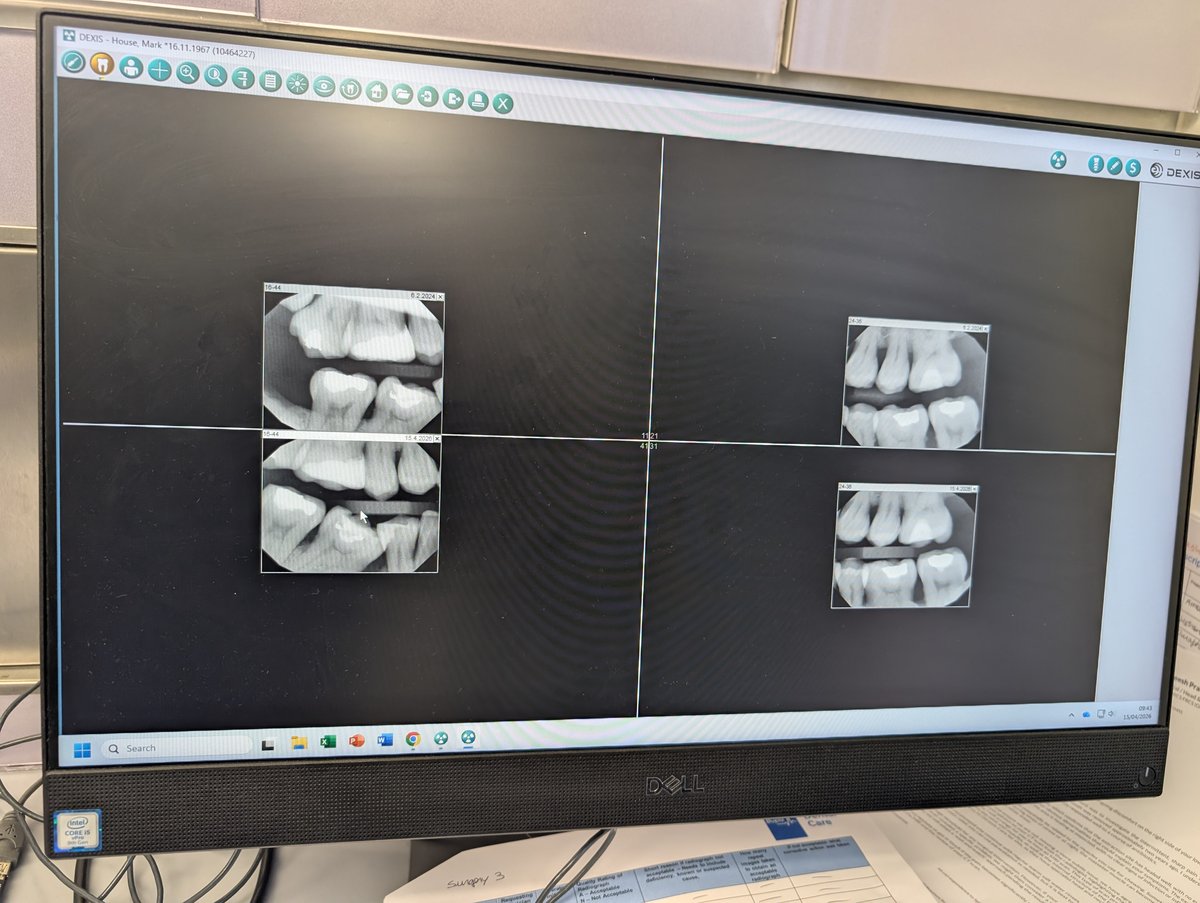
Amodal completion in the surgery
Earlier we’ve written about amodal completion. This the way humans effortlessly “fill in” missing information to perceive complete objects. You see a cup partly hidden behind a book and you just see a whole cup, not a weird clipped fragment. Computers, for the most part, still see fragments.
Dental X‑rays are full of fragments. Teeth overlap. Restorations flare and bloom. Tiny movements blur edges. Bone becomes a gradient of greys that only makes sense if you already know what bone ought to look like.
Yet as my dentist flicked between the two sets of images, it was obvious that he wasn’t really seeing flat pictures. He was seeing a three‑dimensional mouth. He could talk about structures that weren’t actually visible in the strict sense: the continuation of enamel behind an overlap, the true position of a contact point partly obscured, whether a smudge was likely to be caries or just a projection artefact. He was completing the image in his head.
That is amodal completion in the wild. And it is exactly what expert assessors do when they look at a scanned essay, a portfolio or a design. They see the idea behind the typography, the understanding behind the spelling, the design intent behind the shaky pencil line. They infer what isn’t perfectly rendered.
Current AI systems are powerful pattern‑matchers on what is explicitly visible. They are less good at this kind of deep, embodied “seeing through” to the underlying construct. That gap matters.
Why trust beats perceived accuracy
The other thing I became very aware of, lying back in the chair, was how much this all relied on trust.
I don’t follow my dentist’s advice because I’ve audited his diagnostic accuracy statistics. I follow it because, over time, he has proved to be thoughtful, transparent and willing to explain. I trust his judgement. That trust is what converts words into behaviour.
If I didn’t trust him, the same recommendation would land very differently. I might agree politely and then ignore it. The objective quality of the judgement wouldn’t matter; my behaviour wouldn’t change.
Assessment lives or dies on the same distinction. A system can produce technically excellent numbers, but if teachers don’t trust the way those numbers are produced, they override them or disengage. If students don’t trust their results, they treat them as arbitrary and stop using feedback to improve.
One of the reasons RM Compare works is that it feels aligned with how professionals already think. “When I look at these two pieces of work, which is stronger?” is a question they recognise and feel qualified to answer. The process respects their expertise instead of attempting to bypass it. That makes the outcomes more trustworthy, and trust is what ultimately changes what people do.
AI as amplifier – and as a crutch
Several companies have pitched tools to his practice that promise to read radiographs, spot early issues and standardise diagnoses. He was interested, but cautious. For him, AI looks like an amplifier. It can highlight areas worth a second look, provide a kind of spell‑checker for obvious misses, and give some reassurance on consistency.
But then he said something that really stayed with me: “For me this is helpful. For some of the younger colleagues, I worry it might actually be unhelpful.”
The reason is simple. He has decades of tacit knowledge. His inner model of teeth, bone and disease progression is rich. When an AI system draws a red box and says “possible cavities”, he has the confidence to say “no, that’s just an artefact” and move on. The AI is one more voice in the room, not the deciding vote.
For a newly qualified dentist, that inner model is still forming. Their amodal completion is less robust. Faced with the same red box, it’s much harder to disagree. Over time, the risk is that they learn to trust the software more than their own observations, and that the very skills they need to develop are quietly atrophied.
This is the classic danger of automation bias: when the presence of an apparently authoritative system makes people stop looking as carefully, or stop backing their own (correct) instincts. The tool that was meant to support expertise can end up hollowing it out.
Swap “radiograph” for “essay” and the same risk appears in assessment. If we give teachers a single AI‑generated grade and ask them merely to sign it off, we don’t just change the workflow; we change the nature of their expertise. New assessors, especially, may never get to develop the deep, comparative sense of quality that makes human judgement so valuable in the first place.
What this means for RM Compare
First, human comparative judgement has to remain the organising principle. The primary action we support is still a person looking at two artefacts and deciding which better represents the construct they care about. That’s where reliability and legitimacy come from.
Second, if we use AI, it should be in ways that make amodal completion easier, not less necessary. Cleaning up scans, clustering similar pieces of work, suggesting interesting pairings or flagging outliers are all ways to remove friction while leaving the core act of judgement intact. We think about this a lot.
Third, we should think of AI as part of professional development, especially for less experienced assessors. Instead of “here’s the grade”, the more interesting question is “here’s where your judgements differed from more experienced colleagues; what do you notice when you revisit those pairs?” That’s how tacit knowledge grows. Our work around Learning by Evaluating (AKA Assessment as Learning) is central to this.
In dentistry, the best AI will probably be the kind that helps more clinicians eventually “see teeth” the way my dentist does, rather than the kind that tries to see on their behalf. In assessment, I think the same is true.
Back in the chair
At the end of the appointment, my dentist summarised calmly: compared with two years ago, some areas had improved, others were stable, and one needed watching. Nothing dramatic, but enough to nudge my habits in a better direction.
That quiet, comparative judgement grounded in rich tacit knowledge, filtered through a relationship of trust changed what I will do tomorrow morning at the bathroom sink.
That, ultimately, is what we’re aiming for with RM Compare. Whether the artefact is a set of teeth, an essay or a design portfolio, the pattern is the same: support people who can truly “see” the underlying construct, help them compare wisely, and use technology to amplify that human capacity rather than compete with it.