- Research
Using Comparative Judgement to keep exam grades fair when tests change (OFQUAL Research report 2025)

Every year, exams change. New papers are written, formats evolve, and sometimes whole qualifications are refreshed. Yet everyone from students, parents, teachers and universities still expects one simple promise to hold: a grade this year should mean the same as a grade last year.
Behind the scenes, that is surprisingly hard to guarantee. Traditionally, assessment specialists use clever statistics to “equate” different versions of a test. In simple terms, they look for overlap – the same questions appearing on both papers, or the same students taking both versions – and then use that overlap to line scores up on a single ruler.
But real life often gets in the way. High‑stakes questions must be kept secure, so you can’t always reuse them. Curricula change. Assessments move from short questions to extended projects or portfolios. Some cohorts are small or unusual. In those situations, the usual equating tricks simply cannot be used. You still need to keep standards aligned, but your normal tools are no longer available.
So what do you do then?
A different way to use expert judgement
A recent study by Ofqual, the exams regulator for England, explores one answer: lean more deliberately on what experienced examiners do best, namely judging real student work.
Instead of asking examiners to assign marks using a detailed mark scheme, the researchers asked them a much simpler question, again and again:
“Here are two anonymous pieces of work. Which one is better overall?”
Yes! They used Comparative Judgement.
This is not the first time that OFQUAL have taken a close look at Comparative Judgement, but this study takes a significant step forward.
Putting comparative judgement to the test
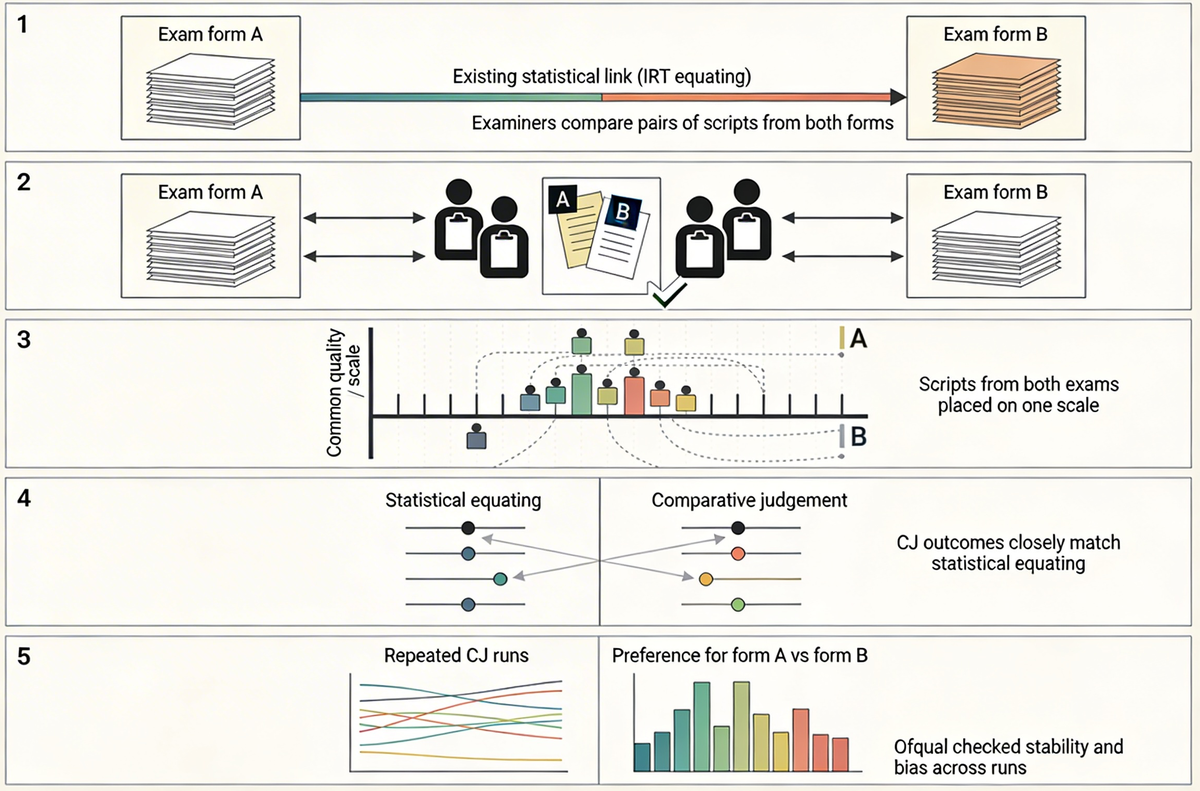
Ofqual’s latest study asked a very practical summative question: can this kind of structured expert comparison help keep standards consistent between two versions of an exam when the usual statistical approaches are off the table?
To find out, the researchers started with two forms of a real exam whose scores had already been linked using robust statistical methods. That statistical link became their benchmark: the best available picture of how the two papers relate to each other.
They then assembled panels of experienced examiners and gave them student scripts from both versions. The examiners did what comparative judgement always asks: they looked at pairs of scripts and chose which was better, taking account of the difficulty of each paper.
By repeating this process many times, under several slightly different design choices, the researchers built a single underlying scale that contained scripts from both versions of the exam. From there, they could ask questions like:
- “If a student scored X on paper A, what score on paper B appears equivalent, according to the examiners’ judgements?”
- “How close is that answer to what the statistical equating had already told us?”
They also repeated the whole exercise to see how stable the results were, and carefully checked for signs of bias – for example, whether judges showed a tendency to favour work from the easier paper regardless of its real quality.
The headline is reassuring. The links derived from comparative judgement sat very close to the links produced by the traditional statistical methods, and they did so consistently across replications, without obvious one‑sided bias.
Why this is such a big step forward
What makes this work so significant is that it plugs a gap the system has lived with for years. We have always known what to do when the technical conditions for traditional equating are met. But in the awkward, very real situations where those conditions break down (new specs, changing formats, small or unusual cohorts) the honest answer has often been: “we’ll do our best, but we can’t really show that standards have been maintained.” Demonstrating that carefully designed comparative judgement can match the behaviour of gold‑standard statistical methods in exactly those scenarios is a genuine leap forward. It gives schools, exam boards and regulators a credible safety net for one of the hardest problems in assessment: keeping grades fair when tests themselves are changing.
Once you accept that, a wider set of benefits comes into focus. If comparative judgement is strong enough to support high‑stakes standard‑maintaining, then using the same designs and tools for “everyday” jobs – moderating coursework, aligning internal tests, running trust‑wide curriculum reviews, or supporting rich formative tasks. It's not experimental, it’s sensible. Because RM Compare uses efficient pairing and adaptive designs, we can cut the number of scripts each judge needs to see, reduce repetitive marking workload, and use your most experienced examiners where they have the most impact.
At the same time, CJ sessions themselves become powerful training environments: new judges can be phased in gradually, see how their decisions align with more experienced colleagues, and build a shared sense of standards over time. That combination of technical robustness, lower workload, smarter judge recruitment and embedded training is why this isn’t just an interesting research result – it’s a practical blueprint for making assessment more sustainable and more humane across both summative and formative, regulated and unregulated settings.
How RM Compare fits in: smart autopilot and manual control
RM Compare is designed to make comparative judgement practical at scale. It lets organisations bring examiners or teachers together online, show them pairs of student work, and turn many simple pairwise decisions into a clear shared view of quality. It already supports two ways of doing this that map neatly onto the kinds of designs explored in the Ofqual research.
The first is Adaptive Comparative Judgement (ACJ). Here, RM Compare acts a bit like a highly organised chair of examiners. It chooses which pairs of scripts to show to which judge next, based on all the decisions made so far. Over time, it learns where the uncertainties are on the quality ladder and focuses new comparisons there. That makes it a very efficient way to build a reliable ranking when you have a large set of scripts and want to use comparative judgement for summative grading, selection, or rich formative feedback.
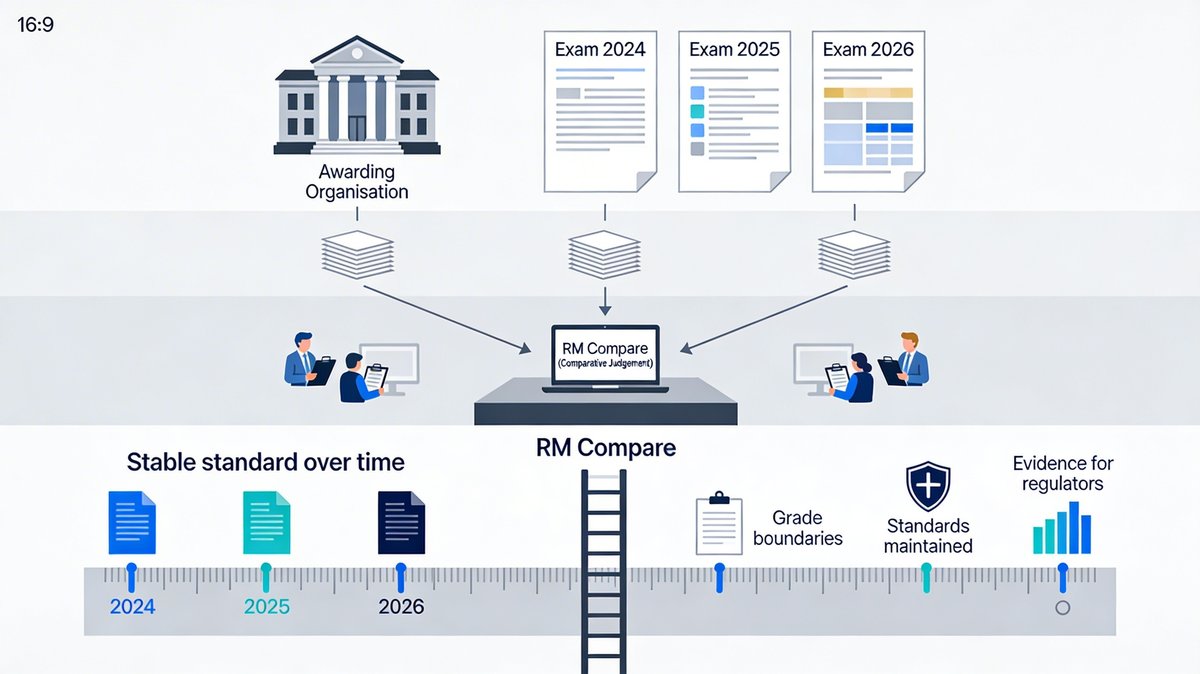
The second is Simplified Pairs. Think of this as manual control for when you have a very specific linking or calibration question in mind. Rather than letting the system choose all the pairs, you can deliberately design the pattern of comparisons: decide which script from Test A should be compared with which script from Test B, how often those key pairs should be seen, and which judges should see them.
That level of control is powerful in standard‑maintaining scenarios. It lets you recreate, inside RM Compare, the kinds of carefully structured designs that researchers and regulators use when they are trying to link two assessments together. You can build a panel, lay out a plan for the cross‑test comparisons you want, run the exercise, and then use the resulting scale to inform decisions about grade boundaries, cut‑scores, or alignment between qualifications.
Put simply, ACJ is your smart autopilot for comparative judgement: ideal when you want to get to a high‑quality ranking as efficiently as possible. Simplified Pairs is your manual flight mode: ideal when what matters most is the exact architecture of the comparisons between two tests.
Beyond regulation: formative assessment and curriculum over time
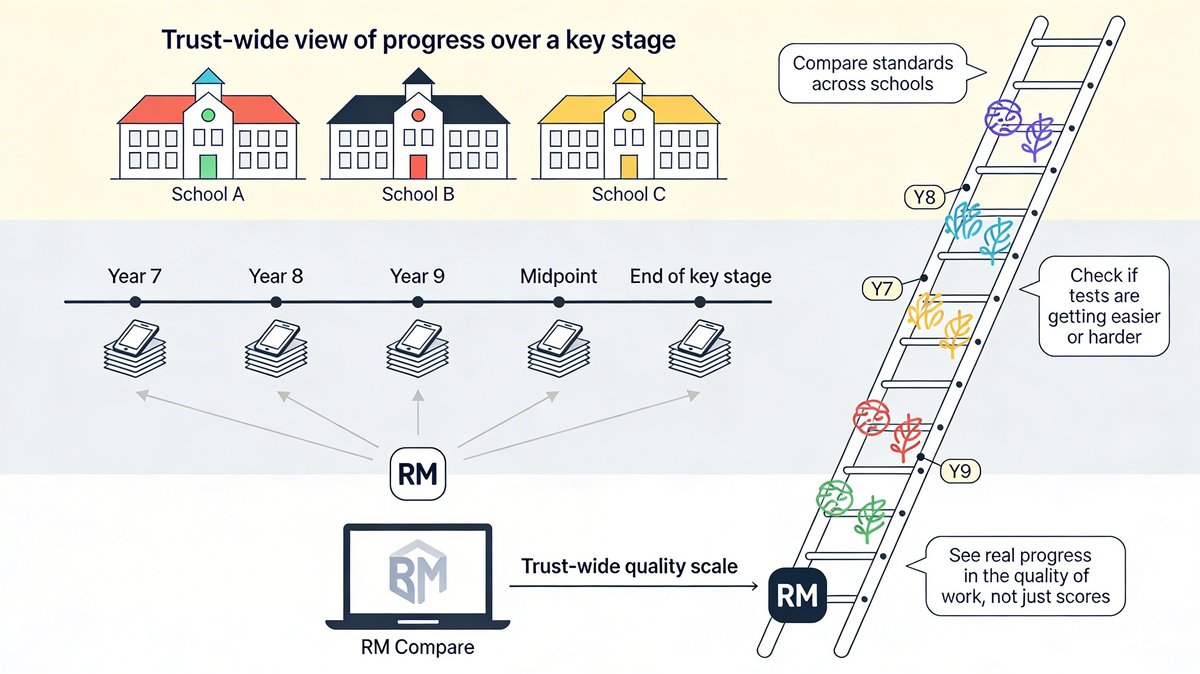
Schools and trusts rely heavily on formative assessments – quizzes, mid‑unit tests, common tasks – to track progress over time. But there is always a nagging doubt: are we seeing genuine learning, or just shifts in how hard our latest test happened to be? Comparative judgement gives them a way to probe that question.
By sampling work from different in‑house tests (within a year and between years) and comparing it side‑by‑side in RM Compare, curriculum and assessment leads can place that work on a shared ladder of quality, regardless of which specific paper it came from. If this year’s “Unit 3” work sits clearly above last year’s on that ladder, they can be more confident that apparent gains reflect real improvement rather than a kinder paper. If it sits lower, they have an early warning that something in the curriculum or assessment design needs attention.
Across a group of schools, curriculum leaders can use the same approach to ask whether they are genuinely expecting the same standard of writing or project work in a particular year group. Cross‑school RM Compare sessions on samples of pupil work let them see how pieces from different schemes of learning, or different schools, line up on a shared standard – and adjust curricula accordingly.
A more human route to fairness – in many settings
For many years, conversations about “keeping standards the same” have been dominated by technical language – common items, common persons, item response theory. That work will always matter in regulated, summative settings. But this new research shows there is also a more human route, grounded in expert comparison of real work, that can deliver results in line with those statistical methods when they cannot easily be used.
And the same core idea extends well beyond exam boards. With tools like RM Compare, schools, colleges, universities and training providers can organise professional judgement – for summative and formative purposes, in regulated and unregulated environments – in ways that are transparent, repeatable and robust. In doing so, they can keep assessment standards fair and credible, even as tests, curricula and technologies continue to change.
What next?
You can read the report in the link below, including the conclusion and recommended next steps.
Curcin M and Lee MW (2025) Evaluating accuracy and bias of different comparative judgment equating methods against traditional statistical equating. Front. Educ. 10:1538486. doi: 10.3389/feduc.2025.1538486
Of course you can also use RM Compare right now to complete your own equating tasks.