- Opinion
A better way to use experts

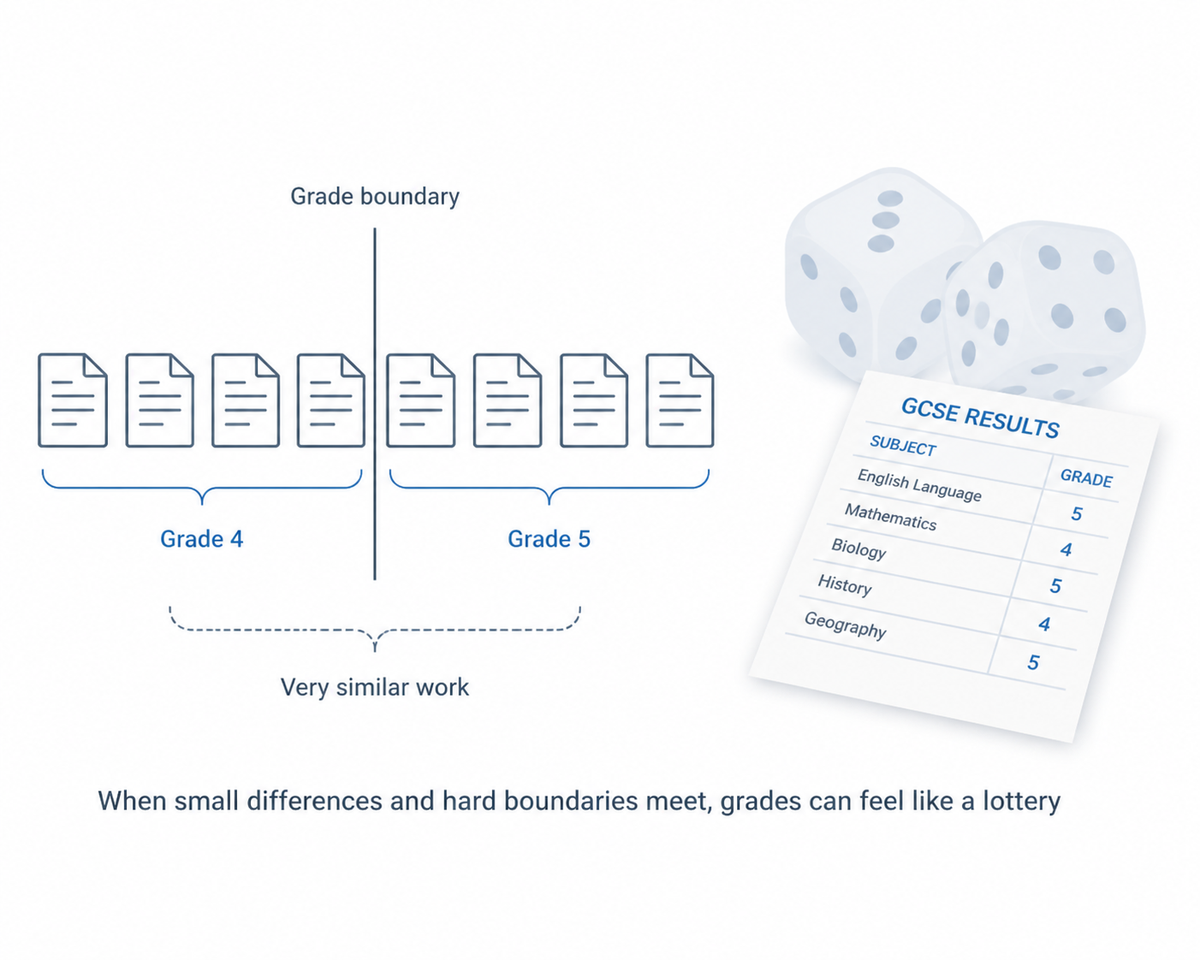
In a recent Observer article, Dennis Sherwood warns that “a single exam result can change a pupil’s life, but grading in England is a lottery.” The piece highlights a stark tension: exam grades carry life‑changing consequences, yet the system’s own regulator acknowledges that many GCSE, AS and A‑level grades are only reliable to within about one grade either way. Put bluntly, thousands of students each summer could have received a different grade if a different examiner had marked their script, or if their work had landed just the other side of an invisible boundary.
The article also draws attention to how much this arrangement rests on trust in “the expert”. We are reassured that experienced examiners have marked the papers, that senior examiners have set the standards, and that regulators have checked the numbers. The public is asked to accept that, despite all the acknowledged uncertainty, this chain of expert judgement is enough to justify treating a single grade as decisive.
At RM Compare, we agree with the Observer that this should trouble us. But we don’t believe the answer is to give up on expertise. Instead, we think the question should be: is there a better way to use experts?
Why the “expert” story no longer feels enough
Most of us still want experts involved in high‑stakes decisions. We do not want our children’s futures decided by a black‑box algorithm or by crude league‑table statistics alone. Teachers, examiners and subject specialists bring hard‑won professional knowledge that deserves to be valued.
At the same time, the traditional story – “your paper was marked by an expert, and checked by another expert” – is no longer sufficient on its own. Research over the last decade has shown substantial disagreement between markers, particularly in subjects requiring extended writing and complex judgement. We have watched appeals turn on the view of one senior examiner rather than any clear notion of consensus, and we have seen grade distributions adjusted statistically in ways that are hard to explain to students who feel they did everything right.
In that context, asking the public simply to “trust the expert” starts to feel like asking them to ignore what they have learned about human bias, variation and error. If we want trust, we have to earn it in a different way.
From “the expert” to expert consensus
There is, however, another way to organise expert judgement.
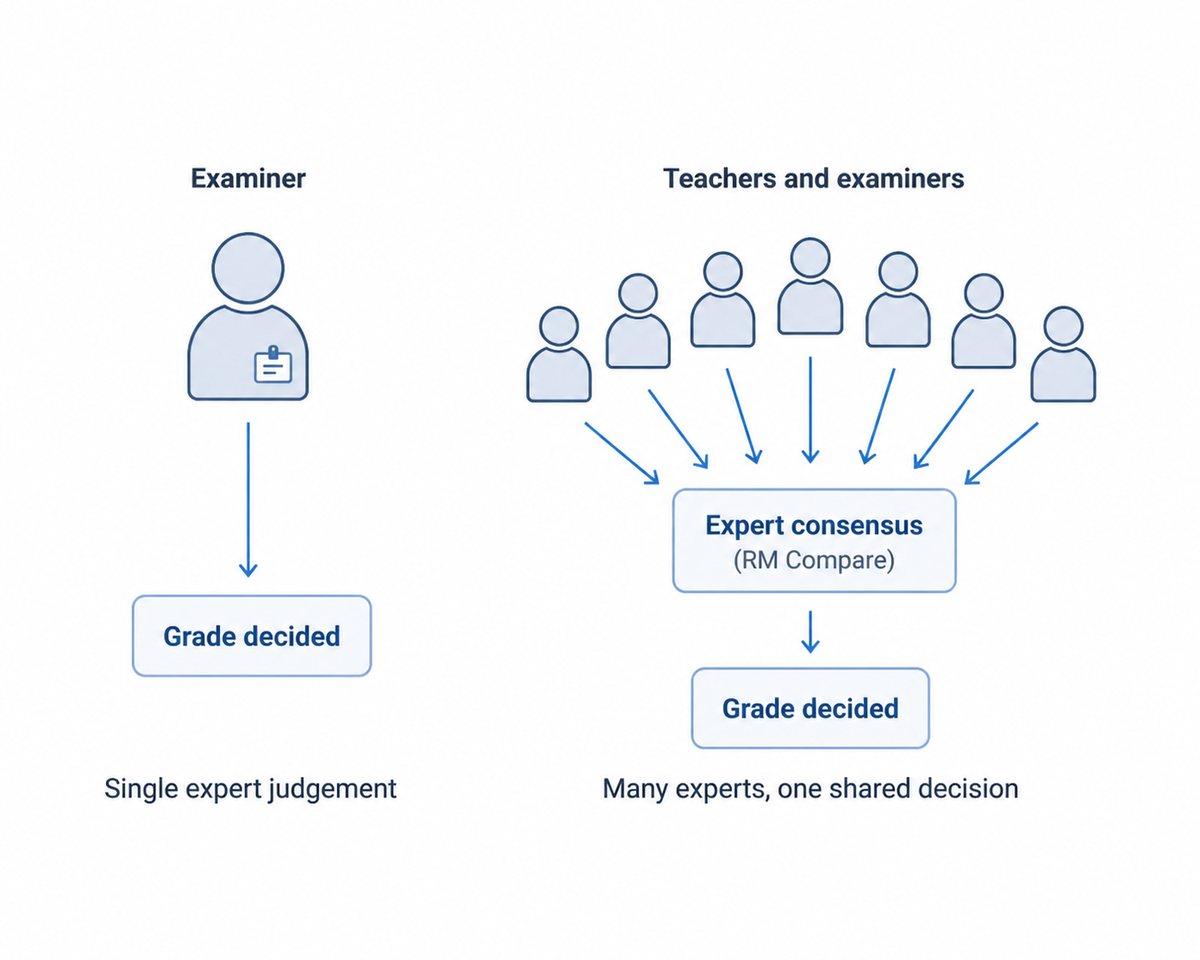
Adaptive Comparative Judgement (ACJ) starts from a simple question: instead of asking one examiner to give every script a score, what if we asked many experienced teachers and examiners to compare pairs of anonymous scripts and decide which one better meets the standard? Each script can be seen multiple times by multiple judges. Over the course of a judging session, a picture forms of where each script sits in relation to the others. The result is not one person’s opinion but a collective, statistically coherent view of the whole set of work.
This is still human expertise, but it is being used differently. Individual judgements are small and local – “of these two, which is stronger?” – rather than absolute. Patterns of agreement and disagreement between judges are measured instead of being invisible. Outlying judgements can be spotted and questioned. The “expert” stops being a single person and becomes the calibrated community of professionals who participated.
From a student’s perspective, that matters. If your script has effectively been located within a rank order built from many such comparisons, its final grade is no longer hanging on how one examiner happened to feel that day. It is anchored in where a broader group of experts believe work of that quality belongs. No system can remove uncertainty entirely, but this is clearly a different proposition from a lone mark on a lone script.
What this means in practice for one script
Thinking about one student’s script makes this more concrete.
First, experts work together to define the standard. Using comparative judgement, a broad sample of scripts from across the mark range is judged by a panel of experienced examiners and teachers. Through those comparisons, a shared understanding emerges of what each grade band looks like in real work, not just on paper in a mark scheme.
Then, routine marking can happen much as it does now – human examiners reading and judging scripts, sometimes with AI tools suggesting marks or highlighting inconsistencies. The crucial difference is that their decisions no longer stand alone. They can be compared back to the consensus standard. If a script’s mark doesn’t fit with what the wider expert community would expect for work of that quality, it can be flagged, looked at again, and corrected if necessary.
For the student, the promise is simple: your result is based on expert judgement, but not on just one expert’s view. It reflects where many experts, working together, place your work.
Where AI fits: tools that answer to experts
The Observer article also gestures towards a wider anxiety: that attempts to “fix” grading might simply replace one opaque system with another, whether that’s a controversial algorithm or a new set of statistical tweaks. Regulators have responded cautiously, allowing AI in supporting roles – for quality assurance, marker training, question generation – while insisting that high‑stakes marking must still involve human judgement.
We agree that the key issue is not whether AI is clever enough to assign marks. The more important question is: compared with what, and controlled by whom?
If we treat collective expert judgement, captured through approaches like ACJ, as a benchmark, then AI can be put in its proper place. Recent proof‑of‑concept work has shown how RM Compare can be used to create consensus‑driven benchmarks that AI models must match before they are trusted in live marking. When models are used to suggest marks or to triage scripts, their behaviour can be monitored against fresh rounds of expert comparison, with misaligned cases routed for human review.
In that model, AI does not become “the expert”. It becomes a scalable assistant whose work is constantly checked against what experts collectively say is fair.
Rethinking appeals: challenging a process, not chasing a different expert
The Observer article also touches a raw nerve around appeals. If grades are uncertain, what exactly are students appealing to? In the current system, an appeal often means asking for a different expert to look at the same script and hoping they see it more favourably. It is a search for a “better” expert opinion, rather than a structured way to ask whether the process treated a candidate fairly.
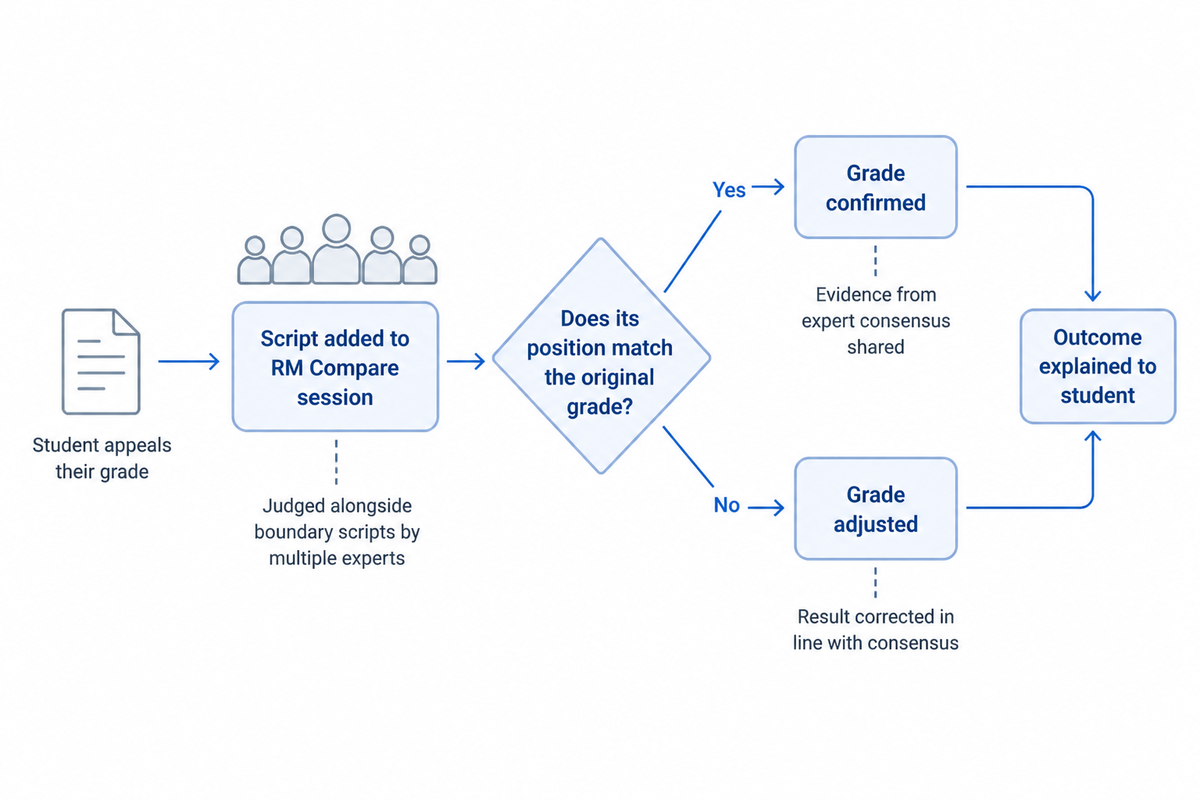
An appeals process built on RM Compare would look different. Instead of pitting one examiner against another, it would ask a more principled question: “Is this script in the right place, given what the wider expert community thinks?” When a candidate appeals, their work can be re‑introduced into a comparative‑judgement session alongside scripts that define the grade boundaries. Multiple judges then decide, through direct comparisons, where it belongs in that ordered set.
If the script consistently wins against work in a higher band, or loses against work in a lower band, there is clear evidence that the original grade needs to be revisited. If, on the other hand, the script sits comfortably where it was originally placed, the candidate and their school can see that the decision aligns with what many experts, working together, believe is fair. The appeal becomes a challenge to the fit with expert consensus, not a plea for a more sympathetic individual examiner.
That kind of appeals process doesn’t just correct more decisions; it also changes the story we tell. Instead of “we found a better expert”, we can say “we checked your result against what experts, as a group, think this level of work is worth – and here is the evidence”.
Keeping experts – but using them better
Dennis Shewrood is right to worry about an exam system that can feel like a lottery, especially at the grade boundaries. But the solution is not to abandon experts, nor is it to hand everything to machines. The way forward is a better use of expertise.
That means organising many expert judgements so they reinforce each other, documenting where they agree and where they don’t, and designing AI and human workflows that are fair by construction. It means moving from a system where one anonymous examiner’s decision carries more weight than it ever realistically can, to one where a student’s grade reflects what a community of experts, working together, judge to be right.
That is the vision we are pursuing with RM Compare. Exams still need experts. But instead of asking one expert to decide everything, we now have a better way to use experts – one that reflects what we know about human judgement, makes thoughtful use of technology, and gives students, parents and teachers a more honest basis for trust.