Blog
Posts for category: AI Validation
-

The Human Skill That Still Eludes AI – And Why Assessment Needs Ground Truth
AI is arriving in education as if it were a cure‑all for workload and consistency. Sales decks promise tools that “judge writing like teachers”, “skip marking altogether”, and “cut workload by 90 per cent”. It is an attractive story in a system under pressure. But if we listen carefully to the people building these systems – and to the artists responding to them – a different story emerges.
-

If AI Is Serious About Learning Outcomes, ‘Ground Truth’ Has to Mean More Than Last Year’s Exam Scores (Part 2/2)
In Part 1 of this series, we asked who gets to define “learning” in an AI world and argued for a human‑grounded validity layer alongside AI‑native analytics. That conversation becomes very concrete when you look at one small, easy‑to‑miss element in OpenAI’s Learning Outcomes Measurement Suite diagram
-

Who Gets to Define “Learning” in an AI World? (Part 1/2)
OpenAI’s new “Learning Outcomes Measurement Suite” is more than a product announcement; it is a bid to define how AI‑mediated learning will be measured – and, by implication, what will count as learning in the years ahead
-
Defending Epistemic Integrity in the Age of AI Assessment
Why a grade must be more than just a plausible statistic. It must be a justified belief rooted in human understanding.
-
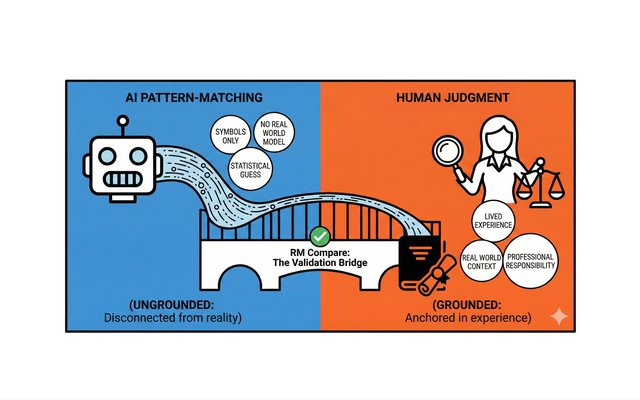
The Validation Layer: Why AI Needs a Human Anchor to be Safe
We are currently living through an "Assessment Arms Race." On one side, students and job candidates are using Generative AI (like ChatGPT) to produce "perfect" essays and CVs in seconds. On the other side, institutions are rushing to buy AI marking tools to grade that work just as fast. It is a closed loop of machines grading machines. And in the middle of this loop, the human element - the actual understanding of quality - is quietly disappearing.
-
RM Compare as the Gold Standard Validation Layer: Recent Sector Research and Regulatory Evidence
In 2025, the educational assessment sector experienced a step change in the evidence base supporting Comparative Judgement (CJ) as a validation layer—bolstering the RM Compare approach described throughout this paper. Major independent studies, regulatory pilots, and industry-led deployments have converged on the effectiveness, reliability, and transparency that CJ-powered systems provide for AI calibration and human moderation alike.
-
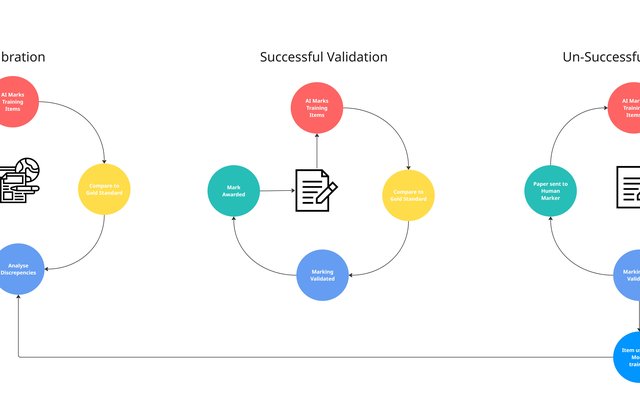
Fairness in Focus: The AI Validation Layer Proof of Concept Powered by RM Compare
In today’s rapidly changing educational landscape, the key challenge isn’t just whether AI can mark student work, but how to ensure every mark is reliably fair. With that mission in mind, our latest proof of concept was designed to demonstrate why RM Compare is uniquely positioned as the foundation for trustworthy, scalable automated assessment.
-
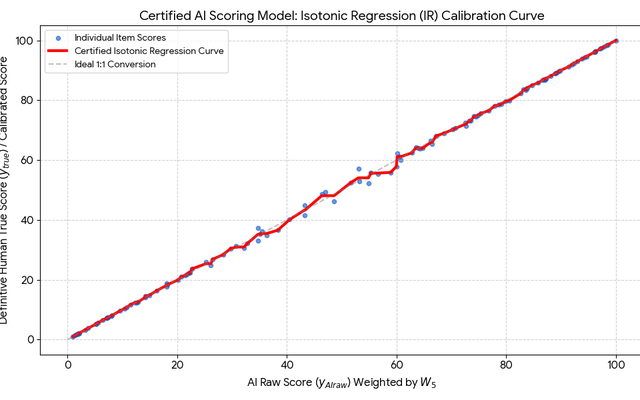
Who is Assessing the AI that is Assessing Students?
As AI steps into the heart of education, we celebrate the speed and efficiency of machine-marked assessments. But a deeper question shadows every advance: If an AI can now judge student work, who—if anyone—is judging the AI? Could an RM Compare AI Validation Layer be the answer?