Blog
Posts for category: AI & ML
-

Why the Discrepancy Between Human and AI Assessment Matters—and Must Be Addressed
As AI-powered tools increasingly participate in educational assessment, a critical challenge comes into sharp focus: AI judges very differently from humans. This difference is more than technical; it threatens the fairness, trust, and validity of assessment systems if left unaddressed.
-

New 6 Part Blog Series - "All Judgements Are Comparisons”: The Human Foundation Beneath AI Assessment
At the heart of every debate around assessment, whether about student work, creative output, or performance reviews, lies a deceptively simple truth that all judgements are comparative. This insight isn’t just a philosophical curiosity, it is the key to understanding why trust and validity in marking are so challenging in an era of artificial intelligence.
-

Blog Series Introduction: Can We Trust AI to Understand Value and Quality?
Artificial intelligence is becoming deeply embedded in how we teach, learn, and assess. But as LLMs and automated marking tools step into spaces once reserved for humans, a fundamental question emerges: can AI truly understand what we mean by quality and value?
-

Variation in LLM perception on value and quality
Can LLM's understand concepts of 'value' and 'quality' in the same way as humans do? If not what does this mean for AI assessment? We completed a short study to explore more, and to think about some of the implications.
-

Building Trust: From “Ranks to Rulers” to On-Demand Marking
The foundations of modern assessment are shifting. Not long ago, RM Compare introduced “ranks to rulers”: a pioneering process that transformed human judgments—ranking student work by quality—into reliable, calibrated measuring scales that educators and students could trust. Now, new AI validation methods are taking these ideas further, making instant, trustworthy assessment a reality for everyone.
-

'Cognitive Offloading', 'Lazy Brain Syndrome' and 'Lazy Thinking' - unintended consequences in the age of AI
Generative AI and LLMs are everywhere in 2025 classrooms, making teaching and learning faster than ever. But as research in the Science of Learning shows, letting technology do too much of the thinking for us—“cognitive offloading”—weakens the very skills education aims to build.
-
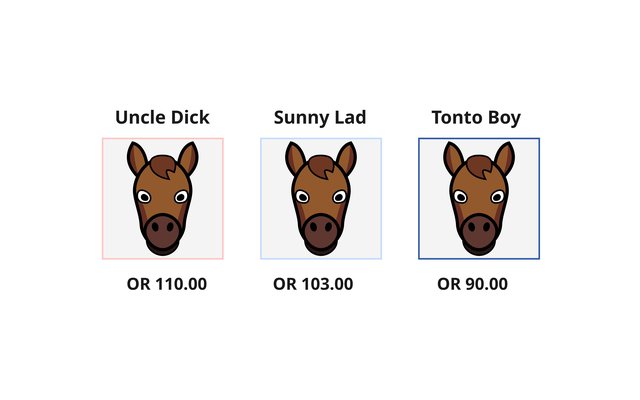
Race to Understanding: Your Item’s “Official Rating” in RM Compare
Ever wanted a single, fair number to sum up how good something is? RM Compare gives each item a Parameter Value—for this blog, think of it as its Official Rating, just like a racehorse at the track.
-

How does the RM Compare AI 'Learn' - New Interactive demo
Learning for a machine is not the same as it is for a human - conflating the two is problematic but all too common. The same is true for Intelligence. With our new Interactive report you can now see how the RM Compare Machine learns.
-

Where's the beef? Learning, Performance, and the Slow AI Revolution
If you’re old enough to remember the classic Wendy’s commercial, you’ll recall the irreverent demand: “Where’s the beef?” In education technology today, with all the sizzle around AI-powered assessment and automation, the same question applies. Are we seeing deeper learning—or just more output with less substance?