- Product
Time for Tea?

We often say that we ‘just know’ a good cup of tea when we see it, but this simple act of recognition hides a profound human capability: tacit knowledge. It is the kind of expertise we carry in our heads but struggle to write down in a manual. While we can easily tell if one brew is 'better' or 'stronger' than another, translating that 'gut feeling' into a rigid score is a task that leaves even the most advanced AI remarkably unstable. As we approach National Tea Day (21st April 2026) , we decided to put this 'Subjectivity Gap' to the test. By asking AI to judge the perfect brew, we’ve highlighted exactly why the most important assessments in life - from classroom creativity to workplace leadership - require a human-centric approach that values intuition over automated guesswork.
Crimes against Tea
To understand why AI struggles with tea, look no further than the viral reactions of Irish comedian Garron Noone. When Garron witnesses 'tea in a can' or tea made in a slow cooker, his visceral reaction isn't based on a lack of data, it’s based on a deep, cultural tacit knowledge shared by millions in the UK and Ireland.
To an AI, a slow-cooker brew might pass a pixel-match test for 'tea colour.' But to a human, the context is all wrong. We don’t just assess the liquid; we assess the ritual, the method, and the intent. This is the 'human premium' in assessment: the ability to recognize when something is technically 'correct' but fundamentally a 'crime' against the standard. If we can't trust a machine to understand why slow-cooker tea is an affront to a nation, how can we trust it to judge the nuance of a student's creative essay or a professional's leadership style?
What we did
We took 6 AI instances (2 from each of Chat GPT, Perplexity and Gemini) through the same assessment process
- Prompt - 'Look' at a Cup of Tea (CoT) and score it out of 20 (1 being 'Very Weak' and 20 being 'Very Strong'. Converted to a % score. (Initial Grade)
- Prompt - Compare the CoT to Colour Chart 1 (Intervention A)
- Prompt - "Review your initial grade" (Post Intervention 1)
- Prompt - Explain how Intervention A equates to the reviewed grade (Intervention B)
- Prompt - "Review your initial grade (Post Intervention 2)
- Prompt - Compare the CoT to Colour Chart 2 (Intervention C)
- Prompt - "Review the initial grade (Post Intervention 3)

What we found
- Each AI Instance changed it's mind as it moved through the interventions. There was no obvious pattern.
- The 6 AI instances failed to agree on very much at all
- Even The 2 instances within each product failed to agree with each other.
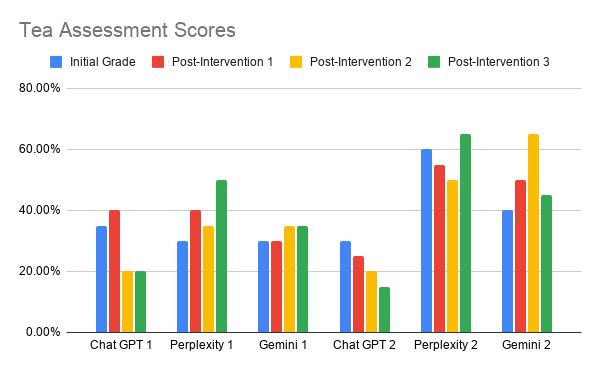
The results are clear: when it comes to the 'nice cuppa,' AI is currently stuck in a loop of digital indecision. By failing to agree with itself or its peers - even when staring at a colour chart - the technology has hit the 'Tacit Wall.' It proves that quality isn't just a data point; it’s a human consensus.
Why this matters for Assessment
The instability we saw in the AI’s tea scores isn’t just about a beverage; it’s a red flag for the assessment of any complex human skill. When we try to force subjective quality into a rigid box, we lose the truth. The implication is clear: the most reliable way to assess "the important stuff" is to stop asking for arbitrary scores and start asking for human comparisons. By doing so, we turn the hidden 'tacit knowledge' of experts into a transparent, trusted, and scalable standard.
What's the point of this? Tea? Who cares?
Hopefully you've ascertained that there is a far wider play here beyond Tea. After all the colour-charts work just fine if anyone is really interested in assessing it. But what about all of those subjective things that we might want to assess that AI also struggle with? This is what Compare has been built for from the outset and now we are moving closer to our long standing ambition to provide an on-demand version.
Is there a better way?
There just has to be right? We can't have machines assessing the really important things in life like Tea - it's not right, and the results (as we have shown) are terrible.
Assessing the quality of Tea, and so many other things we treasure, is a human endeavour and one where comparative judgement can get to the truth, giving reliable, valuable and trusted assessments at scale.
What's even better is that there is a way to do this 'on-demand', even on a mobile device with RM Compare | 📳Live.
There is even the possibility that we can train the AI to do a bit better with our AI validation layer.
Watch this space for more details coming soon.
