- Product
RM Compare has grown up
What began as a powerful way to compare pieces of work is now a complete, production‑ready layer of judgement infrastructure that can sit underneath your existing systems and makes subjective assessment fair, fast, and repeatable at any scale. We’ve reached the point Geoffrey Moore calls the “whole product”: not just the clever core technology, but everything wrapped around it that a mainstream organisation needs to trust it with real‑world stakes.
At the centre is still the Adaptive Comparative Judgement engine, the part that quietly does the hard work of turning thousands of “better or worse?” decisions into a defensible, ranked picture of quality. Around that, however, we have built out the environment that lets real teams in schools, recruitment, awarding, higher education, and training run assessments without needing to improvise processes in spreadsheets or glue different tools together. Roles, permissions, workload controls, quality assurance, reporting, licence centres, multi‑tenant management: all the unseen machinery that turns a good idea into something operations teams can rely on day after day.
Reaching that level of completeness matters because most organisations are no longer experimenting with comparative judgement; they are looking for an assessment backbone. They need to know how work will be captured, how judges will be managed, how data will flow into and out of existing platforms, and how they will meet their obligations around privacy, security, sovereignty, and audit. RM Compare now answers those questions in a joined‑up way. The result is that a trust, a university, or an awarding body can move from “this is interesting” to “this is how we do it here” with far less risk and friction.
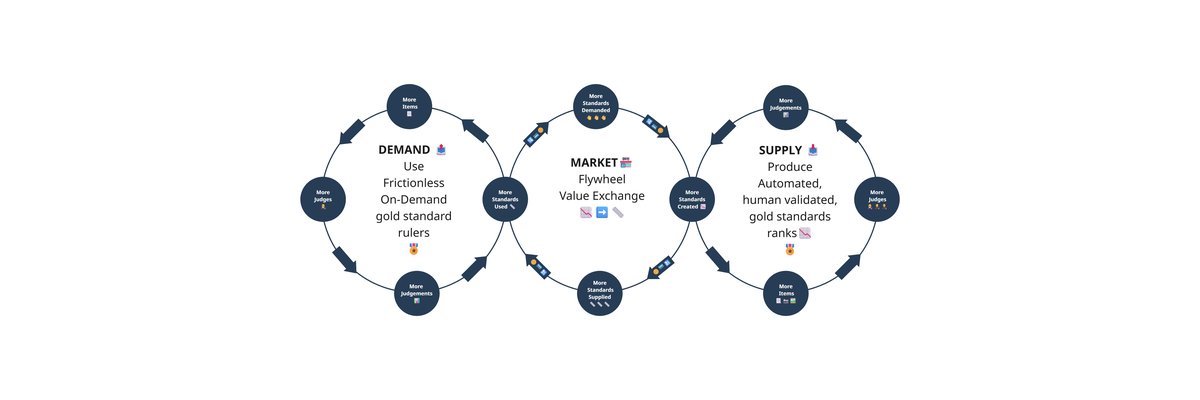
Introducing the RM Compare flywheel
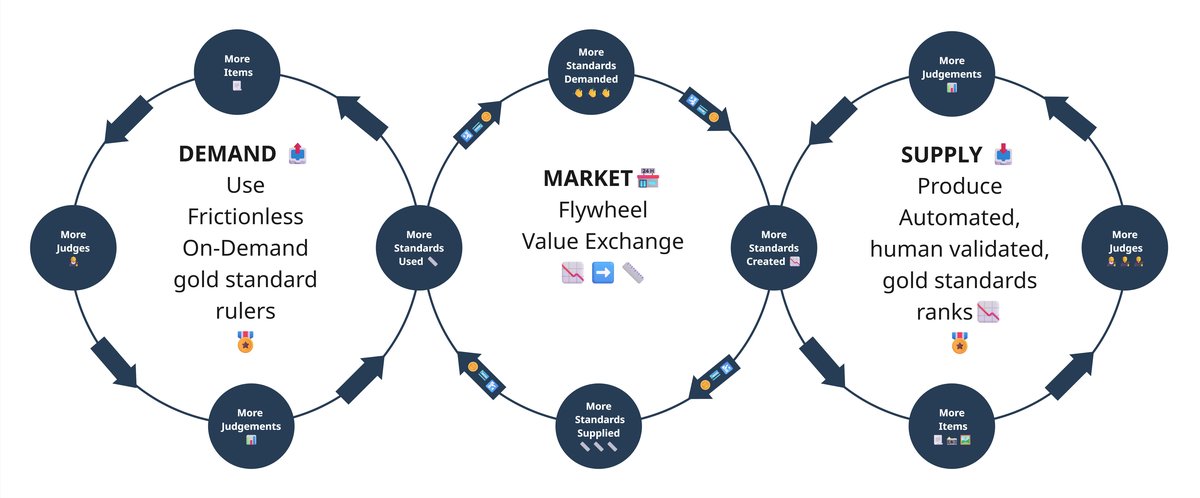
You can see this most clearly in the flywheel at the heart of our proposition. On one side sits demand: the constant need to make sense of essays, performances, portfolios, designs, code samples, interview tasks – all of the rich, subjective work that matters most but is hardest to measure. On the other side sits supply: a growing library of automated, human‑validated gold standards that encapsulate what good looks like in a particular domain. Our system provides a marketplace in the middle, where the two continuously reinforce each other.
When a new assessment runs, judges use the platform to compare work and build a high‑fidelity ranking. From that, we can distil a standard – a ruler – that captures the shared professional understanding of quality in that context. The next time you want to assess similar work, you do not have to start from scratch. You point the new cohort at that ruler and run a frictionless, on‑demand assessment that is quicker to set up, cheaper to run, and easier to explain. Future developments will allow each cycle to make the standards sharper, extends them into new subjects or skills, and prove their reliability in practice. The flywheel turns, and everyone benefits.
This is where the “whole product” really shows through. It is not enough to be able to produce gold standards in theory; you need to be able to deploy them in messy, real environments. The Companion App lets teachers, trainers, and recruiters capture work wherever it happens, from exercise books and sketch pads to whiteboards and physical prototypes, and pull it straight into a judging session. Enterprise infrastructure gives you confidence that, once there, that data is properly governed. You decide which centres can access which standards, how results are shared, and how long data is retained. We provide the engine and the scaffolding; you retain ownership and control.
Interopability
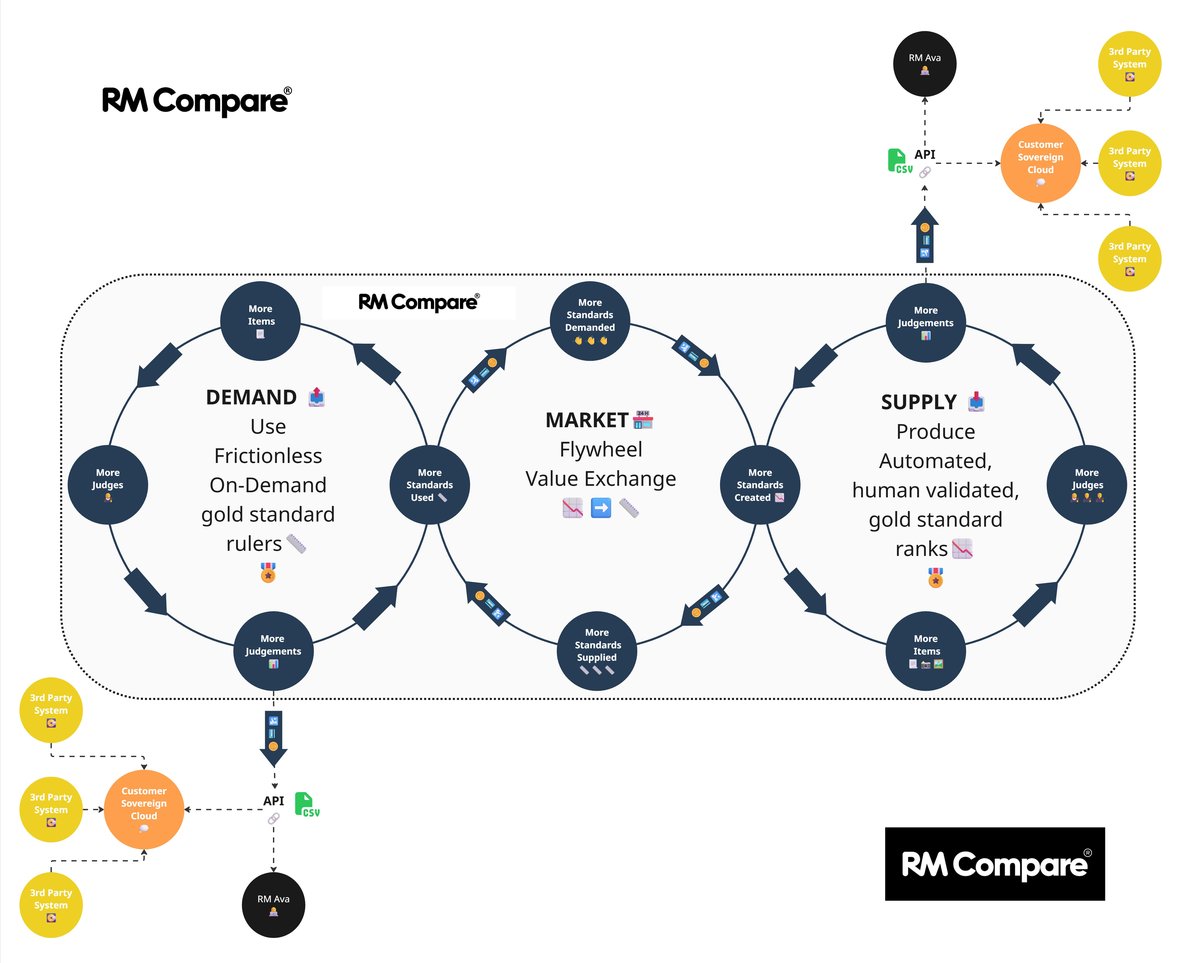
RM Compare - the 'whole' product
Download the flywheel image
{kind=link}
Many organisations already have established platforms for test delivery, candidate management, learning, or analytics. Replacing those wholesale is rarely realistic or desirable. Instead, RM Compare will, over time, expose its capabilities as services that other systems can call. In the future you will be able to trigger a judging session from within an existing assessment platform, surface live progress back into your own dashboards, and feed outcomes directly into the systems that handle grading, selection, or progression. Gold standards become portable assets rather than trapped artefacts; they can be invoked wherever they are needed, inside or outside RM Compare’s own user interface.
This API‑first approach also opens the door for partners and innovators to build on top of our judgement layer. Subject‑specific solutions, sector‑specific workflows, new forms of feedback and coaching: all can be assembled around a common, trusted core, rather than each reinventing the mechanics of comparative judgement for themselves. Over time, that creates an ecosystem where different tools speak a common language of quality, anchored in shared, human‑validated standards.
Privacy and Sovereignty at its core
All of this rests on a clear principle: you provide the fuel and retain the value. Your items, your judges, your judgments, your standards. Our role is to make it possible to capture that expertise, turn it into something reusable, and connect it wherever it can drive better decisions. That is what it means, for us, to have reached the whole product. RM Compare is no longer just a way to run clever experiments with comparative judgement; it is the judgement infrastructure behind a growing number of assessments, programmes, and decisions worldwide.
What next?
If you are wrestling with how to measure the work that matters most – the creative, the complex, the human – then this is the moment when the pieces finally fit together. The engine is proven, the infrastructure is ready, the flywheel is turning, and the APIs are coming. The question is no longer “can we make this work?” but “what do we want to measure next?”
Remember to check out our Roadmap to keep up to date with all the latest developments.